## Hadoop搭建
(其他组件安装最近更新)
一.系统一些基本配置
1.更改网卡配置(克隆之后把另外两台ip改了)
1 | vi /etc/sysconfig/network-scripts/ifcfg-ens33 |
1 | #网卡里面的配置 |
2.重启网卡
1 | service network restart |

3.测试网路是否连通
1 | ping www.baidu.com |

4.关闭防火墙:查看防火墙状态
1 | firewall-cmd --state |

5.临时关闭防火墙,开机还会启动
1 | systemctl stop firewalld |

6.设置开机不启动
1 | systemctl disable firewalld |

7.常用软件安装
1 | yum -y install vim |
8.配置阿里yum源
备份/etc/yum .repos.d/CentOS-Base.repo文件
1 | cd /etc/yum.repos.d/ |
下载阿里云的yum源配置
1 | wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo |
清楚原来的缓存,构建新缓存
1 | yum clean all |
9.添加节点信息
1 | vim /etc/hosts |
1 | 192.168.232.111 master |
10.修改hostname(修改完成后重启生效)
1 | hostname(修改完成后重启生效) |
10.配置节点之间免密访问(在一台机器上执行,再将该节点克隆两份即可,克隆之后在做两次)
在家目录下,执行以下代码生成密钥对,一路回车即可:
1 | ssh-keygen -t rsa -P '' |
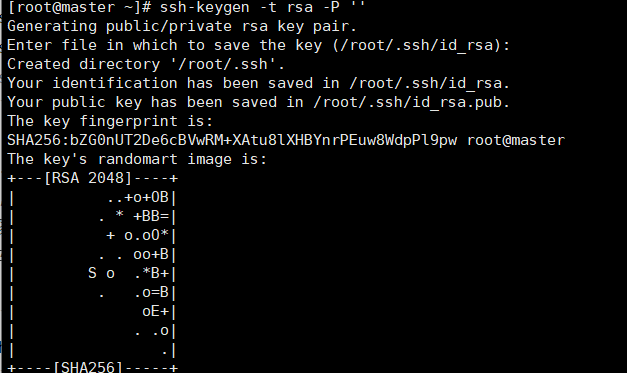
将公钥文件写入授权文件中,并赋予权限
1 | cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys |
11.克隆虚拟机(看图 注意:虚拟机需要关闭)
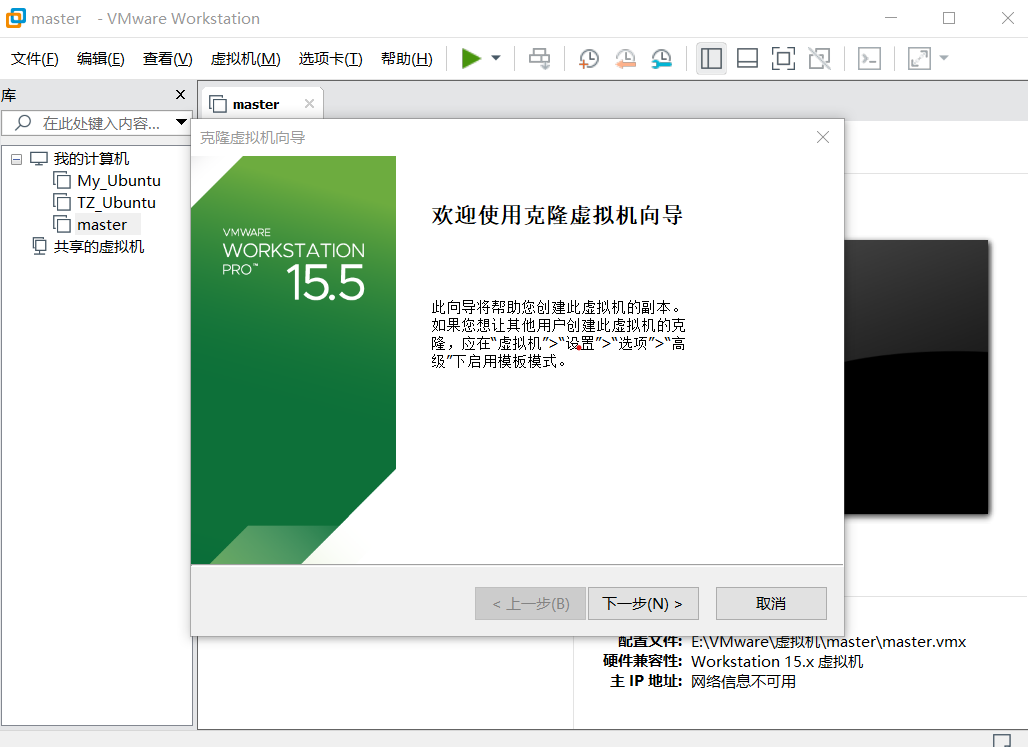
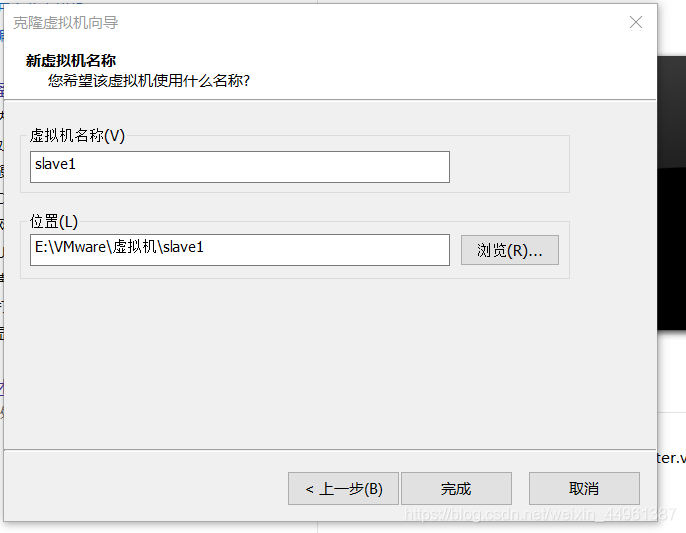

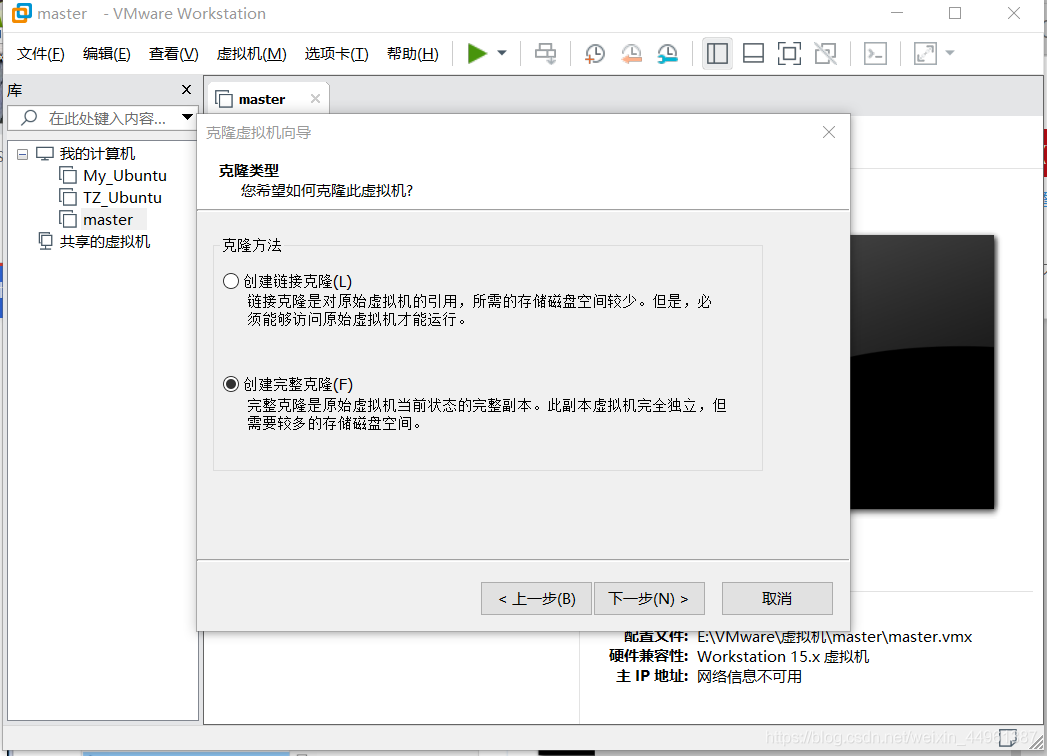
##注意要修改克隆的ip地址以及名称(上面步骤1和10)
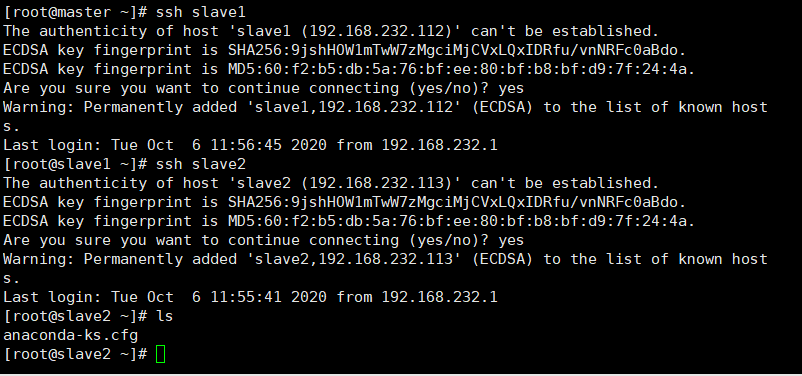
12.节点间免密访问测试(任意两台节点都需要测试,第一次需要输入“yes”)
二.开始安装jdk(可以去官网下载jdk)
自行选择下载jdk(点击百度网盘可以下载) jdk百度网盘链接 提取码:d4cf
用xftp上传jdk-8u162-linux-x64.tar.gz文件到/opt/java(上传完解压文件,然后改名)
/usr/local/java之前用这个目录
1 | mkdir /opt/java |
- 设置环境变量
1 | vi /etc/profile |
1 | #加入下面内容 |
- 执行命令使设置生效
1 | source /etc/profile |
- 验证java是否安装成功
1 | java -version |

6.执行以下命令,在其他两台节点安装(如果ssh没有使文件生效就去子节点再去执行一下)
1 | #给子节点创建java文件夹 |
三.数据库安装
注意:
mariadb和mysql安装一个就行。
MariaDB数据库管理系统是MySQL的一个分支,主要由开源社区在维护,采用GPL授权许可 MariaDB的目的是完全兼容MySQL,包括API和命令行,使之能轻松成为MySQL的代替品。
1.mysql压缩版
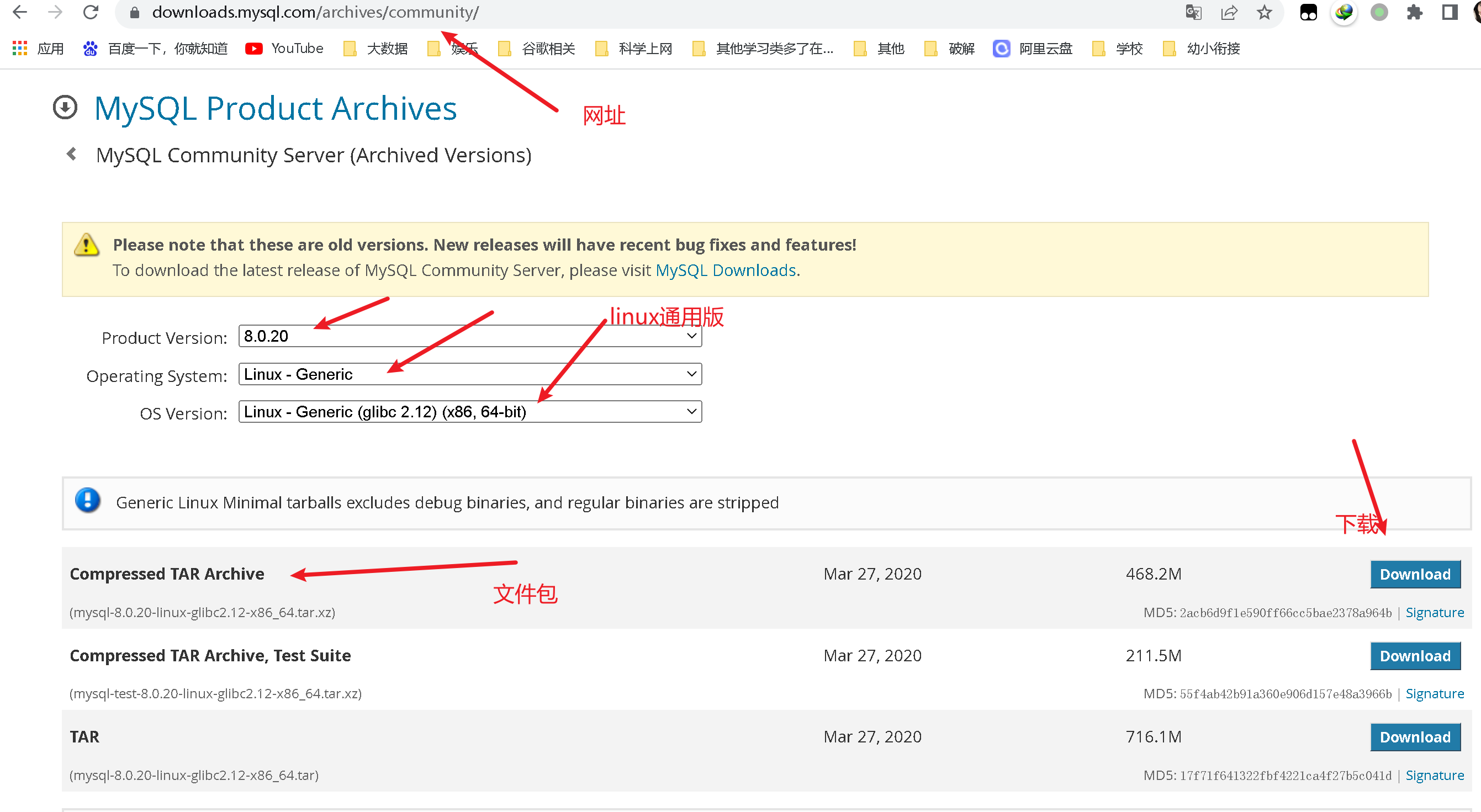
1.下载linux版本安装包
官网下载网址:https://downloads.mysql.com/archives/community/
2.用tabby软件SFTP将压缩文件.tar上传到linux服务器
上传到/opt/software/mysql路径下
3.解压文件安装
1 | cd /opt/software/mysql |
解压图片(后来移动到/opt/software/mysql文件夹中)
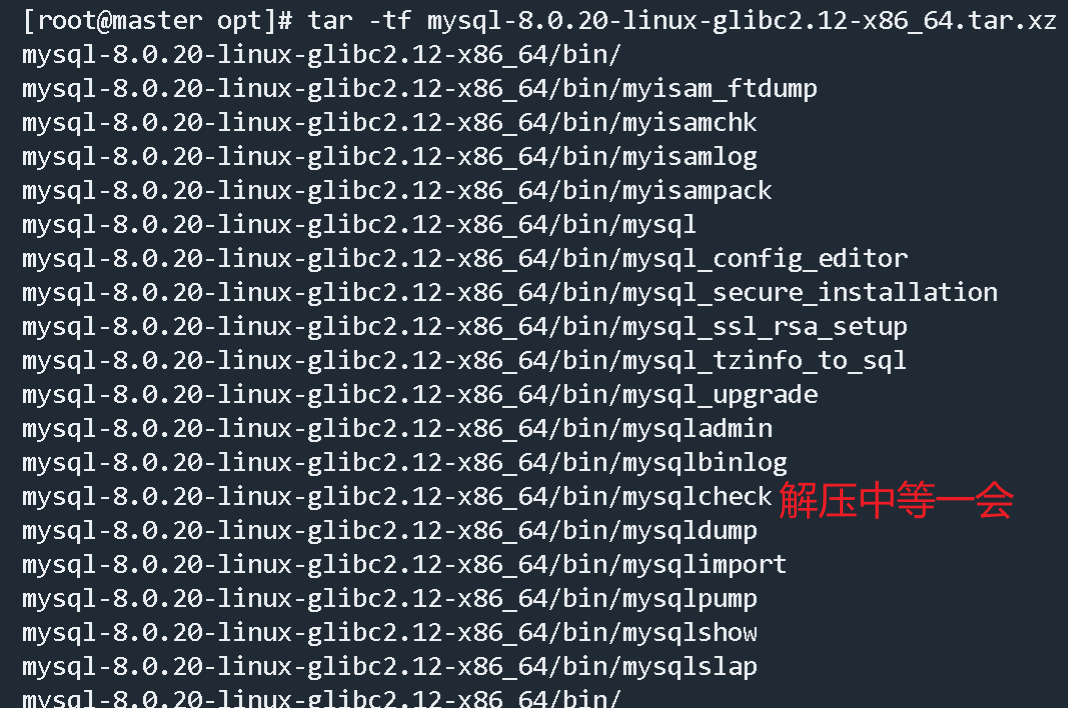
改名字图片

/opt/software/mysql路径下创建一个存放mysql数据的文件夹
1 | 创建文件夹 |
设置配置文件,编译/etc/my.cnf , 内容如下
1 | #查看 |
原版my.cnf文件
1 | [mysqld] |
修改后,英文状态下点击esc -> shift + : -> wq 保存退出
1 | [mysqld] |
注意、注意、注意,很重要,补充知识:(看到就复制下来了)
不要将配置文件中的socket=/tmp/mysql.sock 改为你自定义目录文件的路径,如:#socket=/data/mysql/mysql.sock,非常容易出现一下图片中的错误,处理起来可能费时间和精力,我也像网上说的使用自己的目录且给/tmp/mysql.sock 建立了软连接也不管用,所以还是建议按照我的配置去配置,不要改socket的目录了。

进入/opt/software/mysql/mysql8.0/bin目录下进行初始化mysql,一定要记住初始化输出日志末尾的密码(数据库管理员临时密码)
1 | ./mysqld --initialize --user=mysql --datadir=/opt/software/mysql/data/mysql8.0 --basedir=/opt/software/mysql/mysql8.0 |
如果出现下面错误
1 | [root@master bin]# ./mysqld --initialize --user=mysql --datadir=/opt/software/mysql/data/mysql8.0 --basedir=/opt/software/mysql/mysql8.0 |
解决方法:需要libaio包
1 | yum install libaio |
继续初始化
如果屏幕上没有打印则去日志文件中查看初始化完成后的临时密码:
1 | cat /opt/software/mysql/data/mysql8.0/mysql.err |

1 | 将默认启动文件复制到指定目录 |

将mysql命令添加到系统环境变量
设置环境变量
1 | vi /etc/profile |
1 | #加入下面内容 |
执行命令使设置生效
1 | source /etc/profile |
开机自启动命令
1 | systemctl enable mysqld |
mysql8.0修改密码
1 | ALTER USER 'root'@'localhost' IDENTIFIED BY 'xxxxxxx'; |

开放远程连接(开通后你的mysql就可以让其他远端客户端访问了),执行命令:
1 | use mysql; |
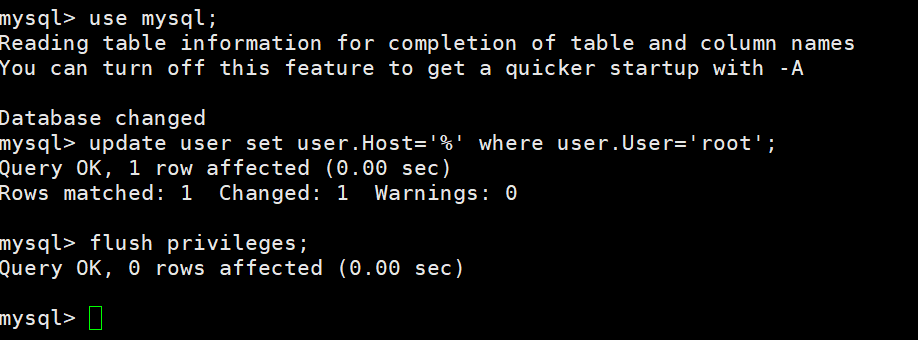
查看防火墙状态,运行状态才能开放3306端口
1 | 查看防火墙状态 |
开放端口
1 | firewall-cmd --zone=public --add-port=3306/tcp --permanent |
关闭端口
1 | firewall-cmd --zone=public --remove-port=3306/tcp --permanent |
查看防火墙所有开放的端口
1 | firewall-cmd --zone=public --list-ports |
在安全组中启用3306端口
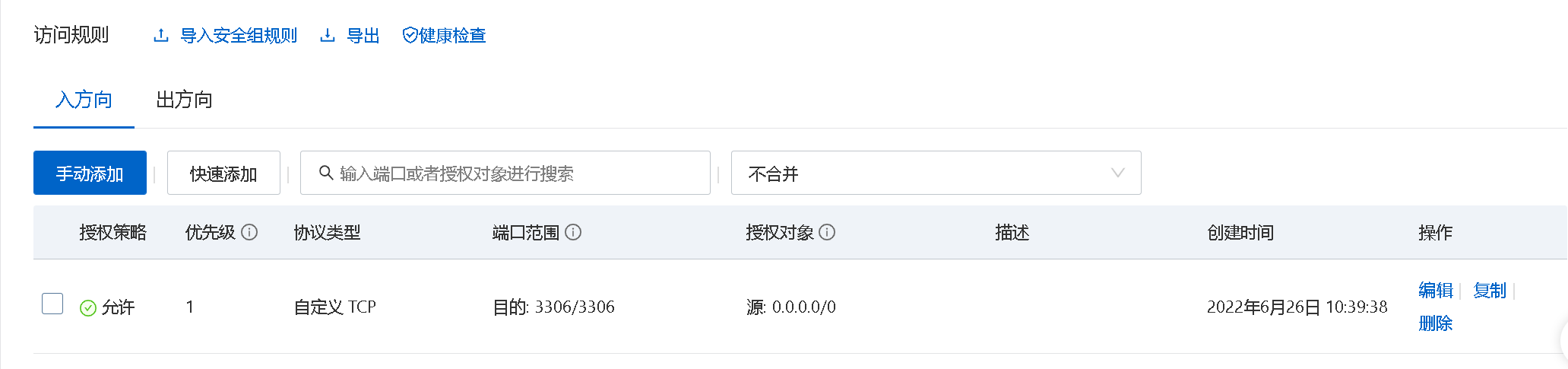
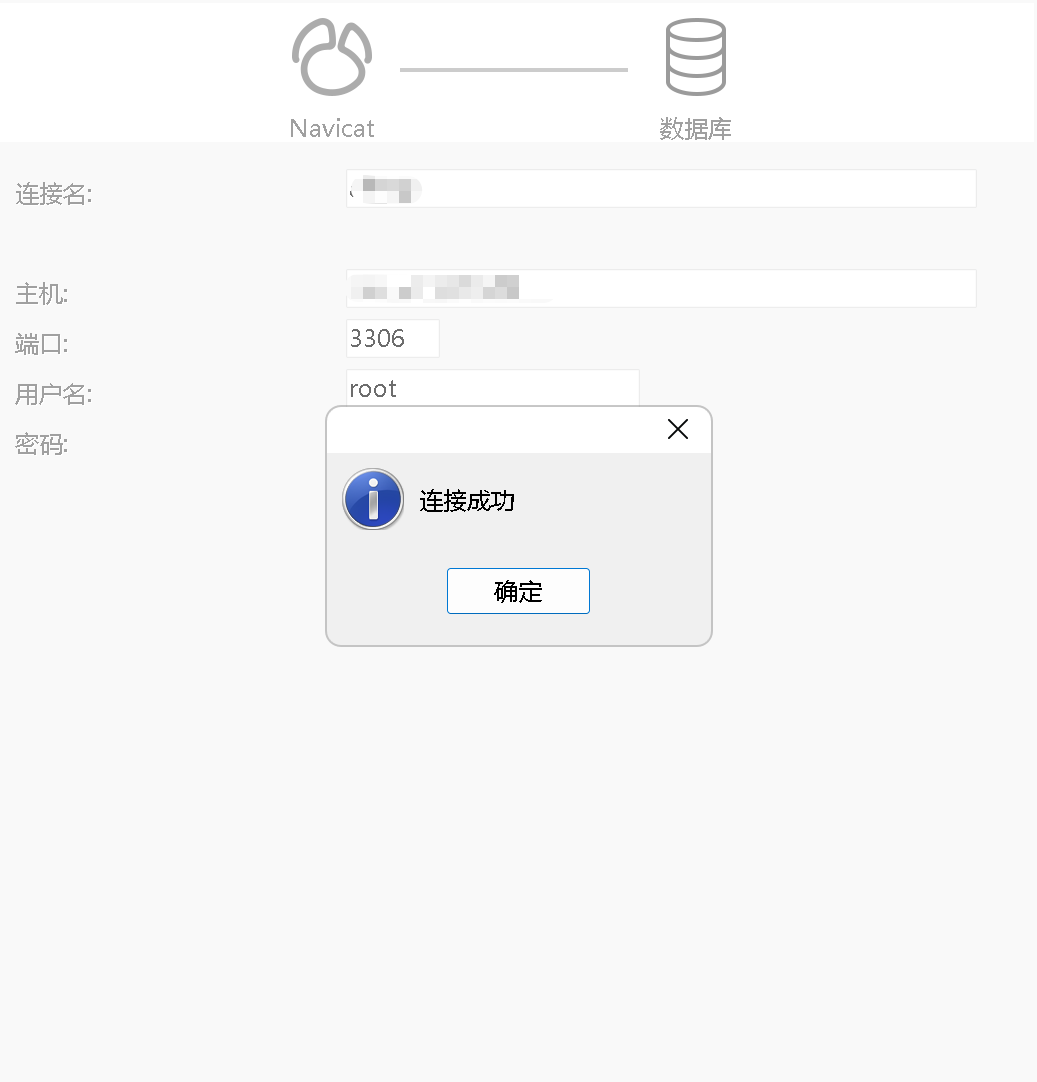
到此,你的mysql已经安装成功,本地电脑的navicat也可以连接开心的使用去吧。
其他问题:如果前面没有出现不用做安装完libaio包继续初始化mysql出现
1 | 2022-06-26T01:23:44.558906Z 0 [Warning] [MY-011070] [Server] 'Disabling symbolic links using --skip-symbolic-links (or equivalent) is the default. Consider not using this option as it' is deprecated and will be removed in a future release. |
解决问题
1 | #创建mysql用户 |
2.yum安装MariaDB完全支持mysql
在云主机中输入:yum install mariadb-server,在线安装Mariadb
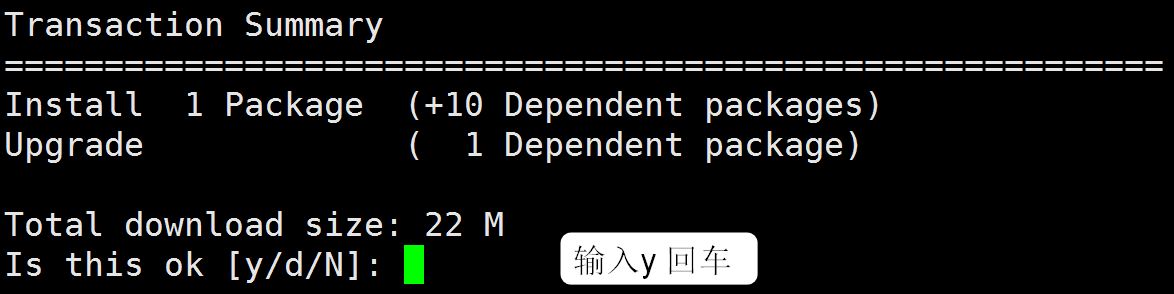
进入自动安装,完毕会有如下提示:
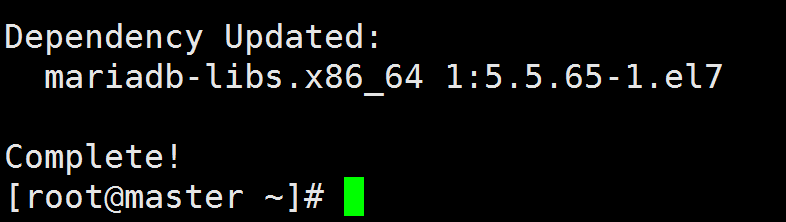
第一次使用MariaDB之前,需要进行初始化操作:
1 | 启动MariaDB |

1 | 登录MariaDB: |
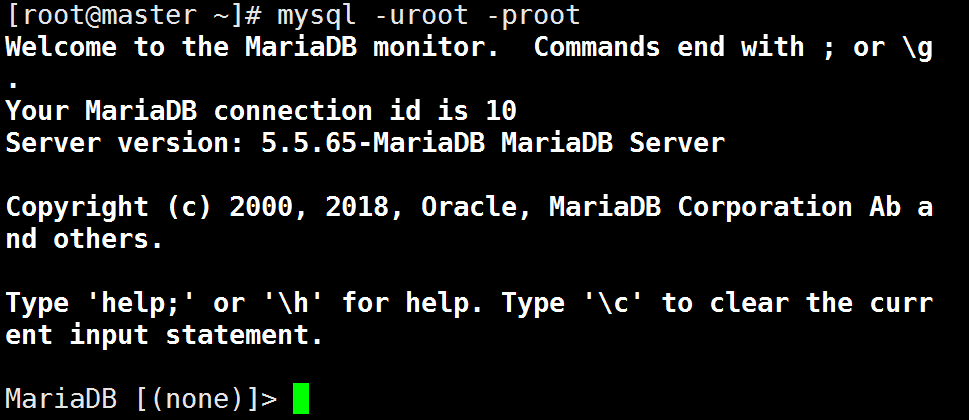
1 | 退出MariaDB |
四.Hadoop安装
- 自行选择下载jdk(点击百度网盘可以下载) hadoop百度网盘链接 提取码:3bq4
- 用xftp上传hadoop文件到/opt/hadoop(上传完解压文件,然后改名)
1 | mkdir /opt/hadoop |
- 配置环境变量
1 | vim /etc/profile |
- 配置env文件(打开hadoop-env.sh,找到“export JAVA_HOME”这行配制jdk路径。)
1 | vi /opt/hadoop/hadoop/etc/hadoop/hadoop-env.sh |
- 配置核心组件文件(/opt/hadoop/hadoop/etc/hadoop/core-site.xml)
1 | vim /opt/hadoop/hadoop/etc/hadoop/core-site.xml |
1 | #编辑的文件(将下列的配置代码放在文件的<configuration>和</configuration>,保存退出即可) |
1 | #创建hadoop数据目录 |
6.配置文件系统(/opt/hadoop/hadoop/etc/hadoop/hdfs-site.xml)
1 | vim /opt/hadoop/hadoop/etc/hadoop/hdfs-site.xml |
1 | #编辑的文件(将下列的配置代码放在文件的<configuration>和</configuration>,保存退出即可) |
- 配置yarn站点文件(/opt/hadoop/hadoop/etc/hadoop/yarn-site.xml)
1 | vim /opt/hadoop/hadoop/etc/hadoop/yarn-site.xml |
1 | #编辑的文件(将下列的配置代码放在文件的<configuration>和</configuration>,保存退出即可) |
- 配置MapReduce计算框架文件()
在“/opt/hadoop/hadoop/etc/hadoop”子目录下,系统已经有一个 mapred-site.xml.template文件,我们需要将其复制并改名,位置不变,命令是“
1 | cp /opt/hadoop/hadoop/etc/hadoop/mapred-site.xml.template /opt/hadoop/hadoop/etc/hadoop/mapred-site.xml |
”,然后,用 vi编辑 mapred-site.xml 文件,需要将下面的代码填充到文件
1 | <property> |
编辑完毕,保存退出即可。
- 配置Master的slaves文件
slaves 文件给出了 Hadoop 集群的 Slave 节点列表。该文件十分重要,因为启动Hadoop 的时候,系统总是根据当前 slaves 文件中 Slave 节点名称列表启动集群,不在列表中的Slave 节点便不会被视为计算节点。
- 用 vi编辑 slaves 文件,我们应当根据自己所搭建集群的实际情况进行编辑。例如,我们这里由于已经安装了 Slave0 和 Slave1,并且计划将它们全部投入 Hadoop 集群运行,所以应当输入如下代码。
1 | vi /opt/hadoop/hadoop/etc/hadoop/slaves |
- 复制 Master 上的 Hadoop 到 Slave 节点(通过复制 Master 节点上的hadoop,能够大大提高系统部署效率。由于我们这里有Slave1 和 Slave2,所以要复制两次。)
1 | scp -r /opt/hadoop root@slave1:/opt |
- 复制Master上的配置文件到Slave节点
1 | #将master节点的配置好的环境变量覆盖到其他节点 |
- 格式化文件系统(该操作只需要在 Master 节点上进行,命令是“ hadoop namenode -format”)
1 | hadoop namenode -format |
- 启动和关闭 Hadoop
- 可以使用 start-all.sh 命令启动 Hadoop 集群。
首先进入 Hadoop 安装主目录,然后执行 shin/start-all.sh 命令,执行命令后,系统提示“ Are you sure want to continue connecting(yes/no)”,请输入yes,之后系统即可启动。 - 要关闭 Hadoop 集群,可以使用 stop-all.sh 命令,
下次启动 Hadoop 时候,无须 NameNode 的初始化,只需要使用start-dfs.sh 命令即可,然后接着使用 start-yarn.sh 启动 Yarn 。 - 实际上,Hadoop 系统建议放弃(deprecated)使用 start-all. sh 和 stop-all.sh 一类的命令,而改用 start-dfs.sh 和 start-yarn .sh 命令。
- 验证 Hadoop 是否启动成功
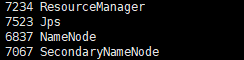
- 用户可以在终端执行 jps 命令查看 Hadoop 是否启动成功。在 Master 节点,执行 jps后如果显示的结果是四个进程的名称: SecondaryNameNode、 ResourceManager、 Jps 和NameNode,如下图所示,则表明主节点( Master )启动成功 。
- 在 Slave0 节点执行 jps 命令,打印的结果中会显示三个进程,分别是 NodeManager、
Jps 和 DataNode ,如下图所示,表明从节点(Slave0)启动成功。其他节点可以类似验证。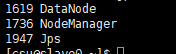
16.jsp中进程解析
五.Hive数据仓库安装(启动hive之前要启动Hadoop命令为:start-all.sh)
1.自行选择下载hive(点击百度网盘链接可以下载) 百度网盘链接 提取码:vauh
1 | #创建文件夹 |
2.用xftp上传压缩文件.gz文件到/opt/Hive(上传完解压文件,然后改名)
1 | #解压文件夹 |

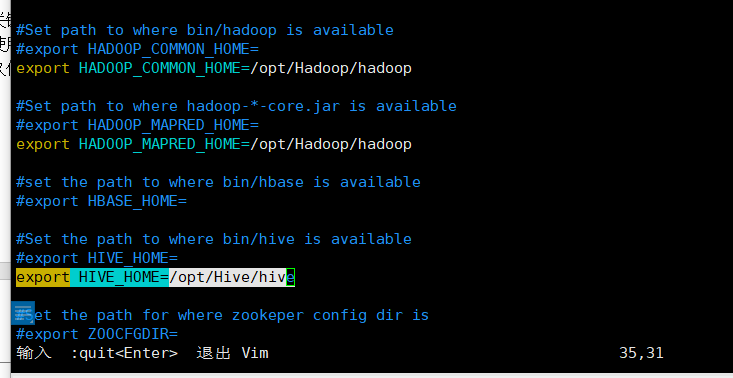
3.配置hive环境变量
1 | #打开文件 |

4.修改hive配置文件
进入conf文件夹查看文件
1 | cd /opt/Hive/hive/conf/ |

1 | cp hive-env.sh.template hive-env.sh |

查看hive-site.xml(如果没有就复制一份模板)
1 | #复制模板(有hive-site.xml文件跳过这一步) |
配置hive-site.xml
1 | vim hive-site.xml |
在文件中添加(汉字是解释,把这一段放在文件最下面,在上面)
1 | <property> |
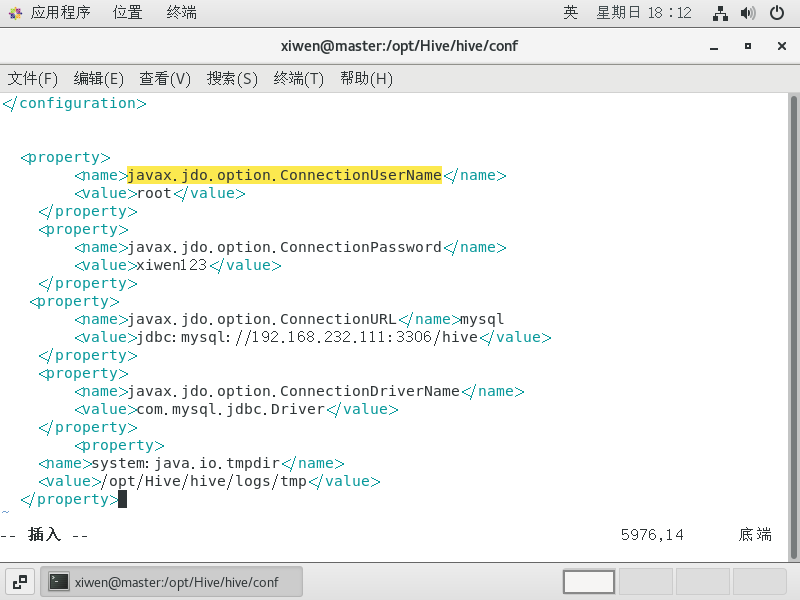
5.用xftp复制mysql的驱动程序到hive/lib下面,百度网盘中的mysql的jar包链接,验证码:h4m1。我用的jar包为:mysql-connector-java-5.1.21-bin.jar
6.在mysql中hive的schema(在此之前需要创建mysql下的hive数据库)
1 | cd /opt/Hive/hive/bin |
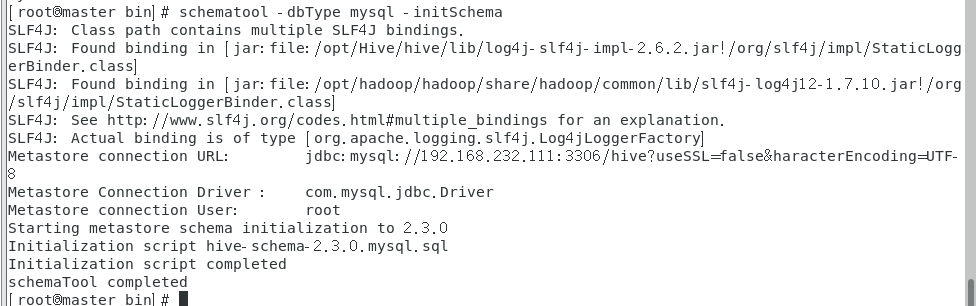
7.执行hive命令
1 | hive |
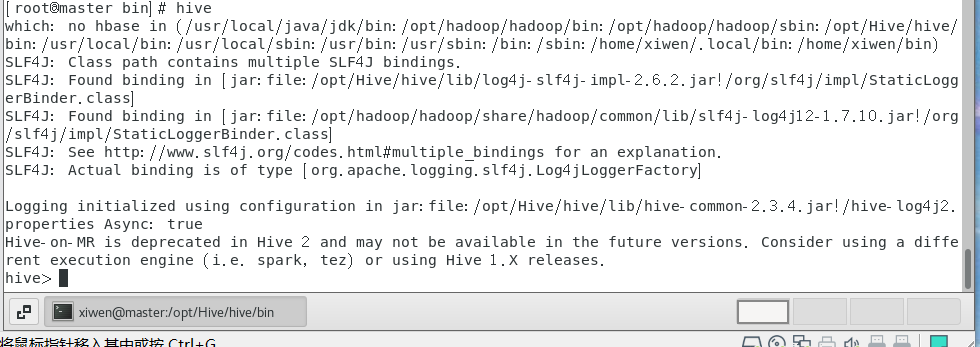
1.出现报错
1 | show databases; |

进入hive文件夹下的conf文件下,找到hive-site.xml
1 | 修改前: |
在查看测试成功
六.Sqoop安装
1.自行选择下载sqoop(点击百度网盘链接可以下载) 百度网盘链接 提取码:bhpf
1 | #创建文件夹 |
2.用xftp上传压缩文件.gz文件到/opt/Sqoop(上传完解压文件,然后改名)
1 | #解压文件 |
3.配置环境变量
1 | #打开文件 |
4.修改配置文件
Sqoop的配置文件与大多数大数据框架类似,在sqoop根目录下的conf目录中。
1 | #进入目录 |
5.拷贝mysql驱动
拷贝上面hive用的mysql驱动到sqoop的lib目录下
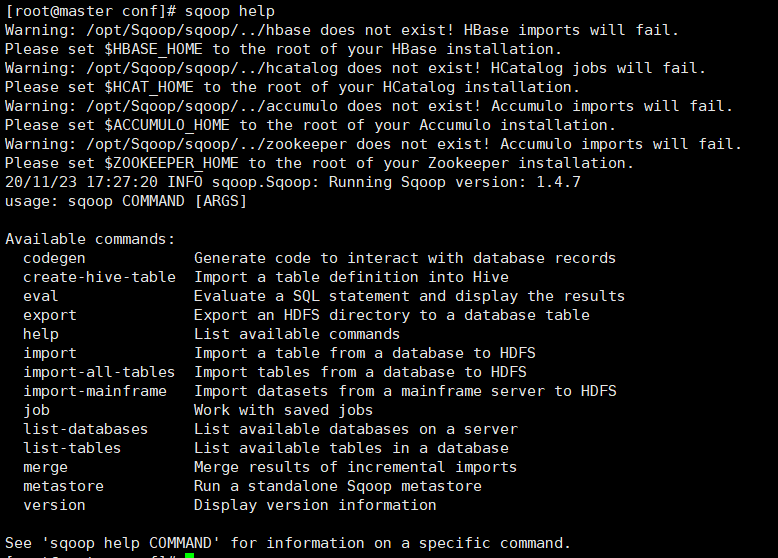
6.验证 Sqoop
我们可以通过某一个 command 来验证 sqoop 配置是否正确:
1 | sqoop help |
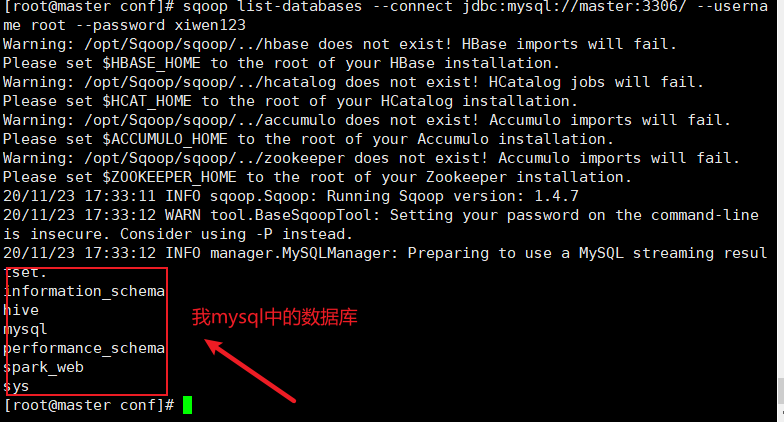
1 | sqoop list-databases --connect jdbc:mysql://master:3306/ --username root --password xiwen123 |
七.安装Tomcat
- 下载Tomcat8.5安装文件
1 | wget https://mirrors.huaweicloud.com/apache/tomcat/tomcat-8/v8.5.63/bin/apache-tomcat-8.5.63.tar.gz |
- 解压缩
将Tomcat安装文件解压缩到/opt目录下:
1 | tar zxf apache-tomcat-8.5.63.tar.gz -C /opt/ |
查看并将文件夹重命名为tomcat-8.5

- 配置环境变量
编辑/etc/profile文件
1 | vim /etc/profile |
vim会开启文档查看窗口,默认情况下不可修改文档内容,可以使用键盘的方向键浏览文档。这里使用↓移动到文档的最后一行,按键盘上的i键进入编辑模式,会看到文档下方提示-- INSERT --,该模式下可以对文档内容进行修改。
在文件最后声明CATALINA_HOME变量,并将$CATALINA_HOME/bin添加到PATH变量中:
1 | export JAVA_HOME=/opt/jdk1.8.0 |
然后按ESC退出编辑模式,输入:wq!保存本次修改并退出vim。
对/etc/profile文件的修改默认不会马上生效,可以使用命令source /etc/profile让本次修改在当前访问中生效。
配置成功后,检查环境变量是否配置成功,可以输入命令:
1 | version.sh |
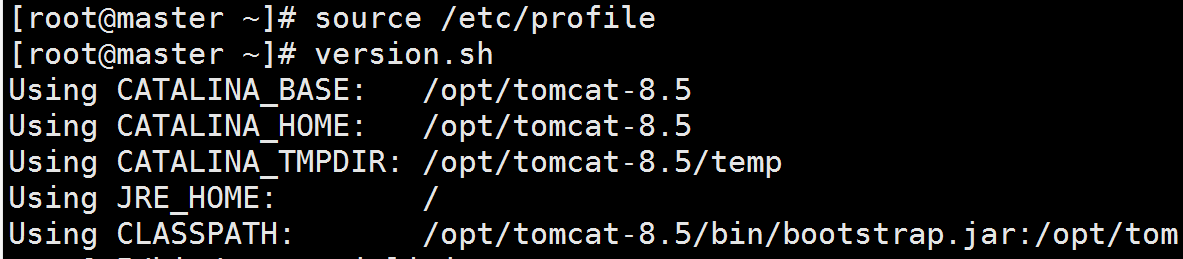
如果可以输出上述信息,则环境变量配置成功。如果提示command not found,则表示配置失败,需要重新对/etc/profile进行配置。
解决Centos7下Tomcat启动过慢的问题:配置JVM使用伪随机函数生成器:
1 | vim /opt/jdk1.8.0/jre/lib/security/java.security |
将117行修改为securerandom.source=file:/dev/urandom

- 启动Tomcat
可以直接使用命令启动Tomcat:
1 | startup.sh |
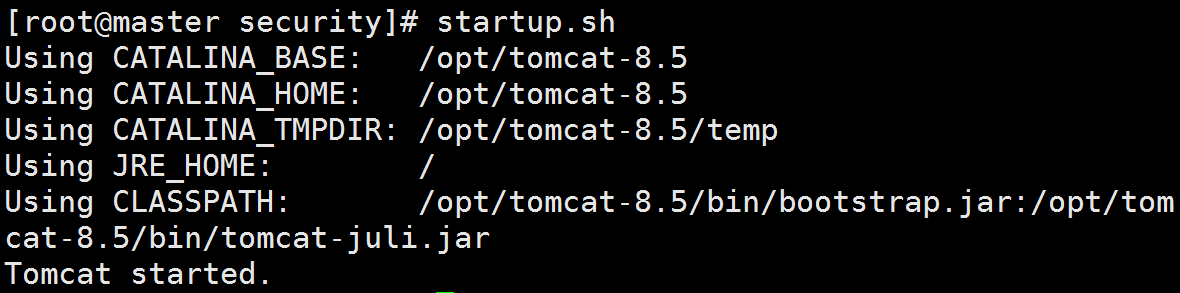
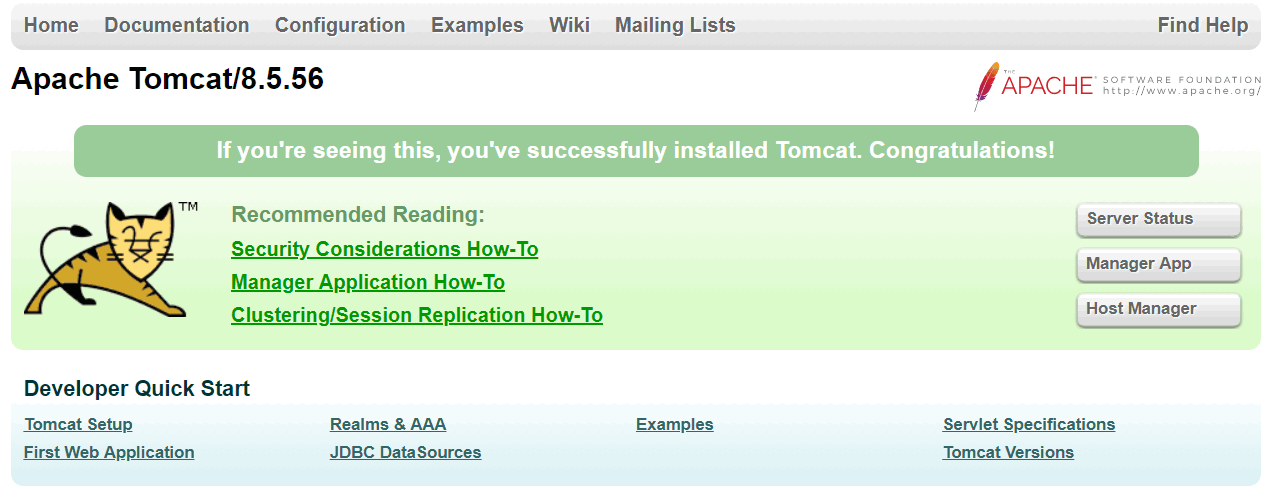
我们可以通过本地浏览器,远程访问云主机上的Tomcat首页。
关闭Tomcat的命令为shutdown.sh。
需要注意,还应该在阿里云主机控制台安全组设定中,添加一条入方向规则,开放8080端口:
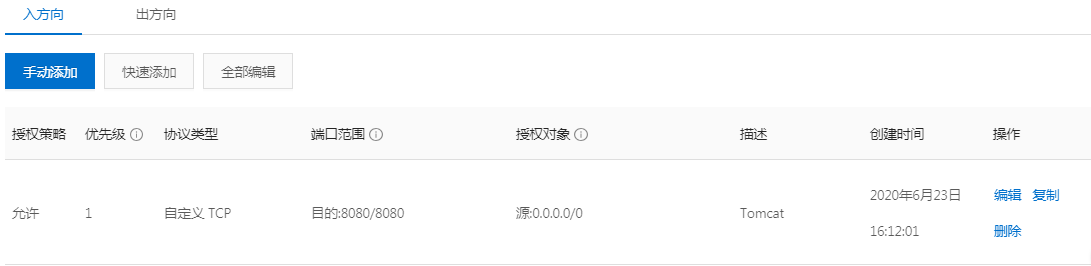
开发端口后,在云主机上启动Tomcat,然后在本地浏览器中输入http://云主机公网ip:8080,可以访问到云主机的Tomcat首页: