Hadoop伪分布搭建文档
[TOC]
1. 准备1台虚拟机或云主机
1) 配置好主机名
配置主机hostname为master
1 | hostnamectl set-hostname master |
2)准备
- 关闭防火墙
1 | systemctl status firewalld #查看防火墙状态 |
- 安装JDK并配置JDK环境变量(参考云主机Web应用环境搭建文档)
- 配置/etc/hosts文件
1 | 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 |
DNS寻址
主机名映射到ip地址

2. 配置SSH免密登录
- master生成密钥
1 | ssh-keygen -t rsa (四个回车) |
- 测试master到本地的免密登录
1 | ssh root@master |
3.安装JDK
- 进入
/opt/software/java目录下
1 | cd /opt/software |
- 下载linux-jdk1.8版本压缩文件到到本地
/opt目录下
1 | wget https://mirrors.huaweicloud.com/java/jdk/8u152-b16/jdk-8u152-linux-x64.tar.gz |
- 解压缩到目录下
1 | tar -zxvf jdk-8u152-linux-x64.tar.gz |
- 查看是否解压成功

配置环境变量
编辑
/etc/profile文件1
vim /etc/profile
vim会开启文档查看窗口,默认情况下不可修改文档内容,可以使用键盘的方向键浏览文档。这里使用
↓移动到文档的最后一行,按键盘上的i键进入编辑模式,会看到文档下方提示-- INSERT --,该模式下可以对文档内容进行修改。在最后一行后面新起几行,添加如下内容:
1
2export JAVA_HOME=/opt/software/java/jdk1.8
export PATH=$JAVA_HOME/bin:$PATH:$HOME/bin然后按ESC退出编辑模式,输入
:wq!保存本次修改并退出vim。对
/etc/profile文件的修改默认不会马上生效,可以使用命令source /etc/profile让本次修改在当前访问中生效。验证是否配置成功,使用
java -version命令
4. 安装hadoop伪分布
1.下载hadoop安装包
1 | cd /opt/software/hadoop |
2.将hadoop2.7.7 解压到 /opt/software/hadoop目录下
1 | tar -zxvf hadoop-2.7.7.tar.gz |
3.配置环境变量
1 | vi /etc/profile |
4.对Hadoop进行配置
- 修改hadoop-env.sh文件,添加jdk
1 | vi /opt/software/hadoop/hadoop-2.7.7/etc/hadoop/hadoop-env.sh |
- 修改core-site.xml
1 | vi /opt/software/hadoop/hadoop-2.7.7/etc/hadoop/core-site.xml |
- 修改hdfs-site.xml
1 | vi /opt/software/hadoop/hadoop-2.7.7/etc/hadoop/hdfs-site.xml |
HDFS的副本数量,伪分布下使用1,完全分布下使用3
- 配置mapred-site.xml
1 | 复制模板文件并配置 |
- 配置yarn-site.xml
1 | vi /opt/software/hadoop/hadoop-2.7.7/etc/hadoop/yarn-site.xml |
5.格式化hdfs
1 | hdfs namenode -format |
6.启动hadoop
1 | start-dfs.sh |
查看hadoop运行情况
每个主机使用jps命令查询
浏览器访问 http://master:50070
注意:云主机需要开放50070端口才能正常访问网页
7.测试Hadoop运行
创建一个临时文件hello
1
2
3
4
5vi hello
hello world
hello hadoop
hadoop将文件上传到hdfs上
1
hdfs dfs -put hello /
查看文件是否正确上传
1
hdfs dfs -ls /
对文件进行词频统计
1
hadoop jar /opt/software/hadoop/hadoop-2.7.7/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.7.jar wordcount /hello /out
查看词频统计结果
1
hdfs dfs -cat /out/part*
删除本例用的hello文件和out文件夹
1
2hdfs dfs -rm /hello
hdfs dfs -rm -r /out
8.配置hadoo中hdfs网页(hdfs网站默认端口50070端口)
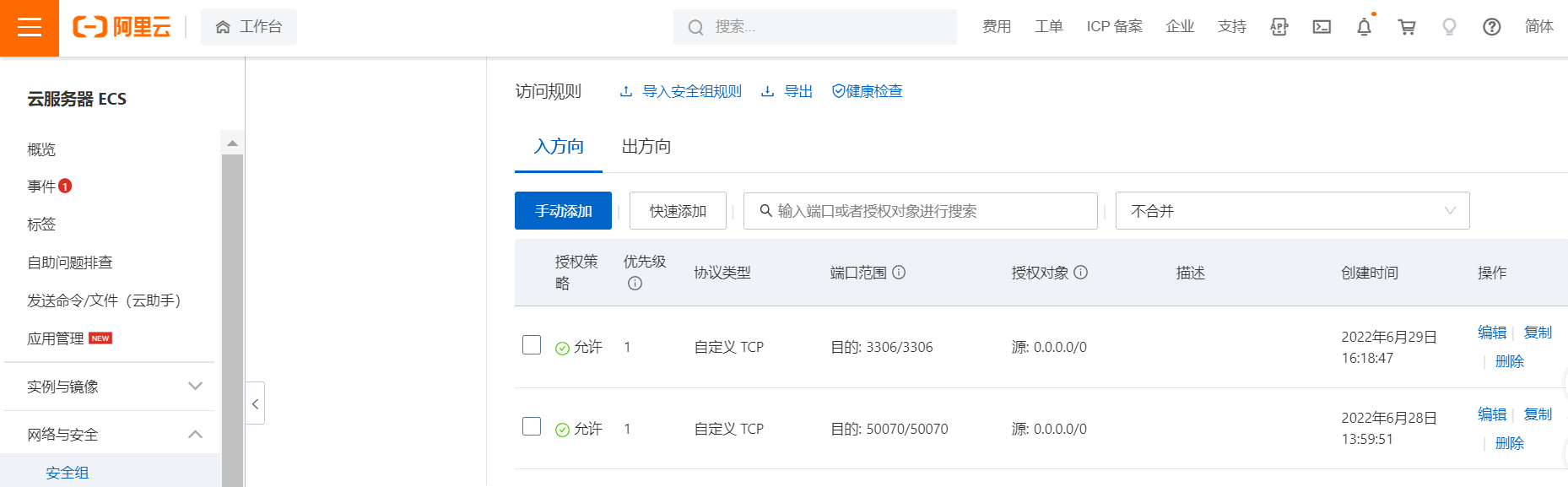
1.在阿里云的安全组中配置入方向50070端口,授权对象0.0.0.0
2.配置完成后http://ip:50070
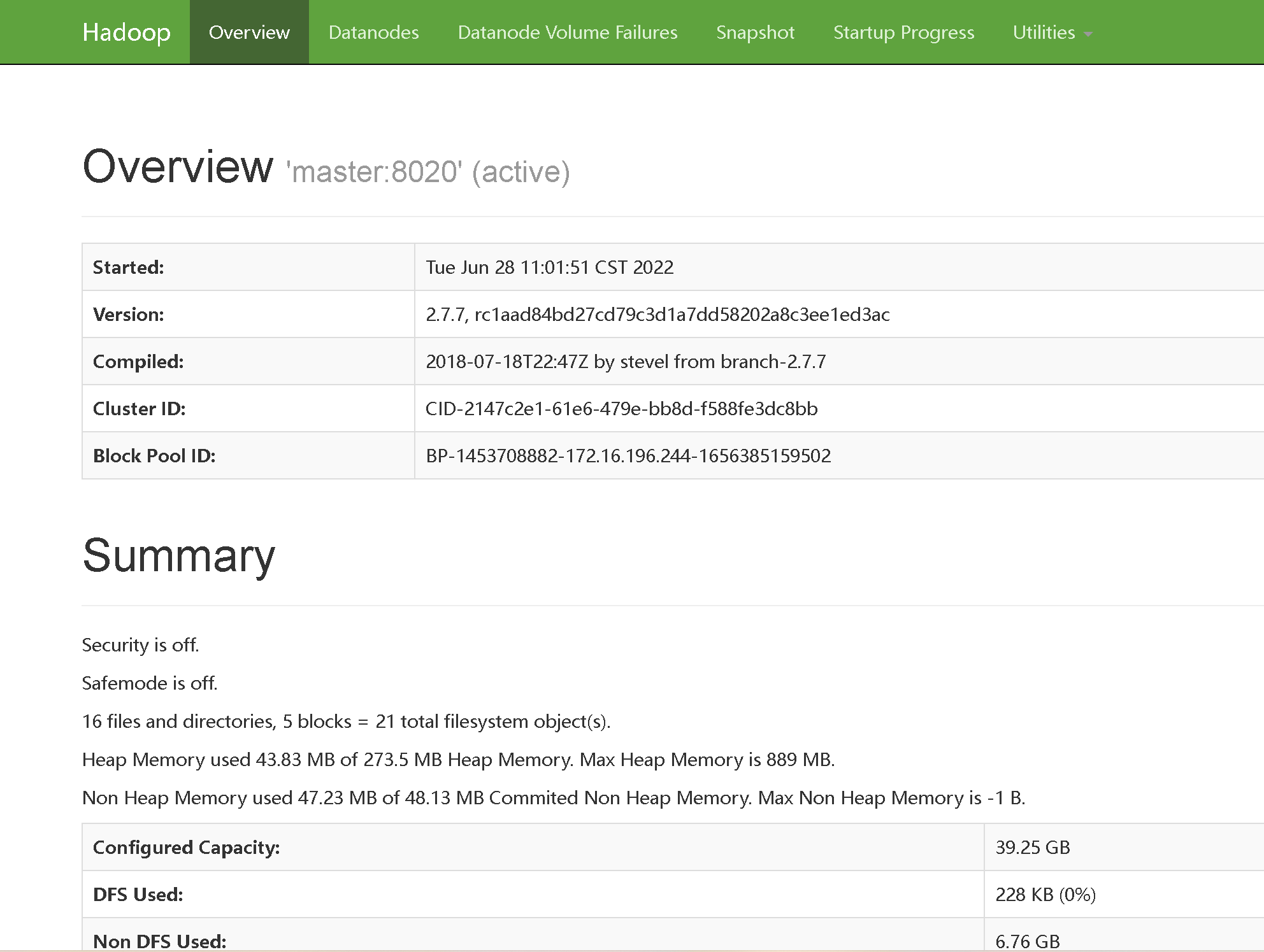
5. 安装Hive
/opt/software/hive/hive-2.3.8
1.获取安装文件
1 | wget https://mirrors.huaweicloud.com/apache/hive/hive-2.3.8/apache-hive-2.3.8-bin.tar.gz |
2.解压缩
1 | tar -zxvf apache-hive-2.3.8-bin.tar.gz |
3.配置环境变量
1 | 编辑/etc/profile文件 |
4.配置Hive
1.配置hive-env.sh
1 | 复制模板 |
2.配置hive-site.xml
正常情况下,应该通过hive-default.xml.template模板文件生成hive-site.xml文件,但是该模板文件内容过多,修改较为麻烦。因此,可以直接通过命令创建一个空白的hive-site.xml文件,将所有需要的配置添加进去。
1 | 创建空白的hive-site.xml文件 |
3.配置Hive的日志目录
Hive中使用log4j2插件进行运行日志的记录,该插件默认将Hive日志保存在本地主机的${sys:java.io.tmpdir}/${sys:user.name}路径下,对初学者来说不容易查找。因此,我们配置修改该路径,将hive的日志保存在/opt/hive/log目录下。后续,hive运行中产生异常时,可以查看该目录下的日志信息,找到具体的异常信息。
1 | 拷贝文件 |
4.将mysql连接jar包添加到hive的lib文件夹下
hive基于JDBC访问Mariadb数据库,因此,需要将mysql连接jar包添加到hive安装目录下的lib目录中,可以直接使用xftp等工具实现这一操作,也可以通过外网直接下载:
1 | wget -P /opt/software/hive/hive-2.3.8/lib https://repo1.maven.org/maven2/mysql/mysql-connector-java/8.0.16/mysql-connector-java-8.0.16.jar |
5.解决SLF4J重复问题
hive和hadoop都使用了SLF4J的jar包,但是版本不同,会造成冲突提示,可以直接删除hive中的SLF4J的jar包:
1 | cd /opt/software/hive/hive-2.3.8/lib |
6.配置MariaDB、或Mysql
mariadb
1 | #进入MariaDB |
Mysql
1 | #进入mysql |
7.初始化Hive的元数据库
1 | 在第一次使用hive前,需要用如下命令初始化hive的元数据库,该命令只能执行1次: |
8.使用Hive
可以使用hive命令启动hive,注意,Hive启动时会直接访问HDFS,Hive的一些操作会继续MapReduce实现。因此需要保证HDFS和YARN已经处于启动状态。 hive
查询当前所有的库
1 | show databases; |
测试Hive
1 | create database testdb; |
6.Sqoop操作文档安装
1 下载安装包
1 | wget http://archive.apache.org/dist/sqoop/1.4.2/sqoop-1.4.2.bin__hadoop-2.0.0-alpha.tar.gz |
2 安装
使用如下命令将sqoop解压到虚拟机的/opt目录下
tar -zxvf sqoop-1.4.2.bin__hadoop-2.0.0-alpha.tar.gz
将文件夹名称修改为sqoop-1.4.7
1 | mv sqoop-1.4.2.bin__hadoop-2.0.0-alpha sqoop-1.4.2 |
3 配置环境变量
使用vim命令编辑文件
vim /etc/profile
export SQOOP_HOME=/opt/software/sqoop/sqoop-1.4.2
export PATH=$SQOOP_HOME/bin:
使本次配置生效
source /etc/profile
检查环境变量是否配置成功
sqoop version
4 添加数据库连接jar包
使用xftp将数据库连接jar包上传到虚拟机的/opt/sqoop-1.4.7/lib目录下
也可以使用如下命令,从hive的lib目录下拷贝数据库连接jar包到sqoop对应目录下
cp /opt/software/hive/hive-2.3.8/lib/mysql-connector-java-8.0.16.jar /opt/software/sqoop/sqoop-1.4.2/lib/
如果未安装Hive,可以直接从官网下载jar包:
wget -P /opt/sqoop-1.4.7/lib/ https://repo1.maven.org/maven2/mysql/mysql-connector-java/8.0.16/mysql-connector-java-8.0.16.jar
阿里云下载地址:
wget -P /opt/sqoop-1.4.7/lib/ https://archiva-maven-storage-prod.oss-cn-beijing.aliyuncs.com/repository/jcenter/mysql/mysql-connector-java/8.0.16/mysql-connector-java-8.0.16.jar
测试
1. MySQL导入数据到HDFS
首先,在MySQL中创建测试用库和表并插入数据:
1 | create database sqoop; |
接下来,使用sqoop命令将widgets表中数据导入到HDFS中:
参数说明:
- import :表示导入数据至HDFS
- –connect jdbc:mysql://……:定义数据库连接的URL
- –username root:指定连接MySQL的用户名
- –password root:指定连接MySQL的密码
- –table widgets:指明待导入的MySQL表名
- -m 1:指定用于导入数据的Map作业的个数ssh
查看结果:
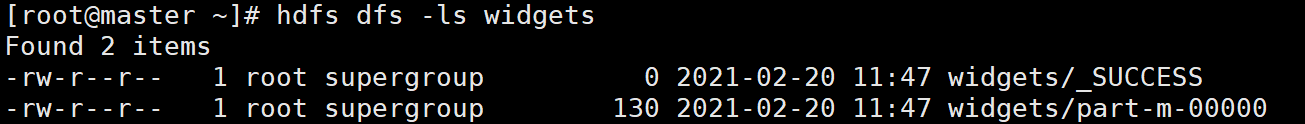
查看HDFS上的数据:

该命令会自动将MySQL表中的数据保存到HDFS上的/user/用户名/表名目录下。
也可以使用 --target-dir /路径来指定导入到HDFS上的路径,如:
1 | sqoop import \ |

2. HDFS导出数据到MySQL
首先,在MySQL中创建接收数据的表格:
1 | use sqoop; |
接下来,使用sqoop命令将HDFS上的数据导出到MySQL中:
1 | sqoop export \ |
参数说明:
- export:表示从HDFS导出数据
- –connect jdbc:mysql://……:定义数据库连接的URL
- –table widgets_from_hdfs:指定导出至MySQL的表名
- –export-dir /……/widgets/part-m-00000:指定导出文件
- –input-fields-terminated-by ‘,’:指明导出数据的分割符为 ,
运行成功后,使用SQL语句查询widgets_from_hdfs表中数据,查看数据是否导入成功:
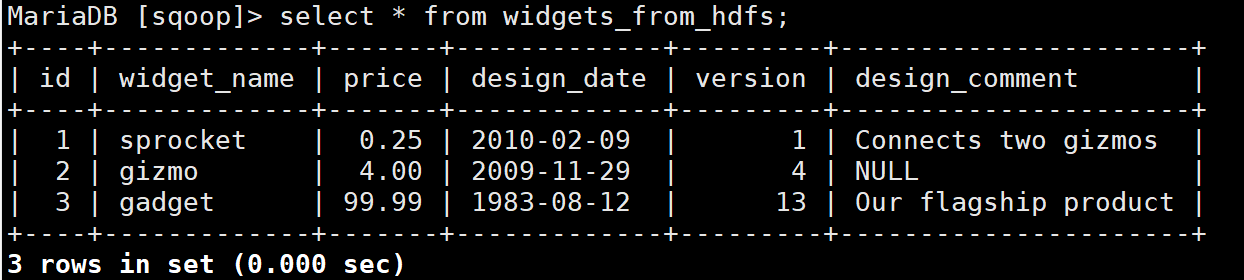
将数据从Hive导入Mariadb
示例需求:将hive中的nybikedb/tb_day_gender_count表中数据导入到Mariadb中
1. 在云主机的Mariadb中创建用于接收数据的表
登录虚拟机的Mariadb
mysql -uroot -proot
以下为mysql中的操作,建表时需要注意表中字段名称和个数需要与hive中的表一致,但是字段类型要调整为mysql的类型,主要就是讲string调整为char或者varchar
create database nybikedb;
use nybikedb;
create table day_gender_count(
day varchar(30) comment '数据的日期',
gender int comment '用户性别,0-未知,1-男性,2-女性',
count int comment '日骑行总数'
);
2. 使用sqoop命令将hive数据导入到Mariadb中
-- 以下在虚拟机的终端中操作,操作前需要启动hdfs和yarn
sqoop export \
--connect jdbc:mysql://localhost:3306/nybikedb \
--username root \
--password aliyun123Xiwen \
--table day_gender_count \
--fields-terminated-by ',' \
--export-dir /hive/warehouse/nybikedb.db/day_gender_count
其中:
--connect:指定连接的关系型数据库的url--username:关系型数据库的用户名--password:关系型数据库的密码--table:关系型数据库中的表名--fields-terminated-by:要导入的数据文件的分隔符,即hive中声明表时使用的字段分隔符--export-dir:hive表对应的数据在HDFS上的存储目录,目录的最后一级对应的是hive上的表名
如果hive中的目标表使用了分区,那么sqoop导出数据时会抛出异常,因为目标文件夹下不是数据文件,而是分区的子文件夹。这里可以在hive上新建一张临时表,去掉分区信息,并保证数据的顺序,再使用sqoop导出该表的数据到Mariadb中。
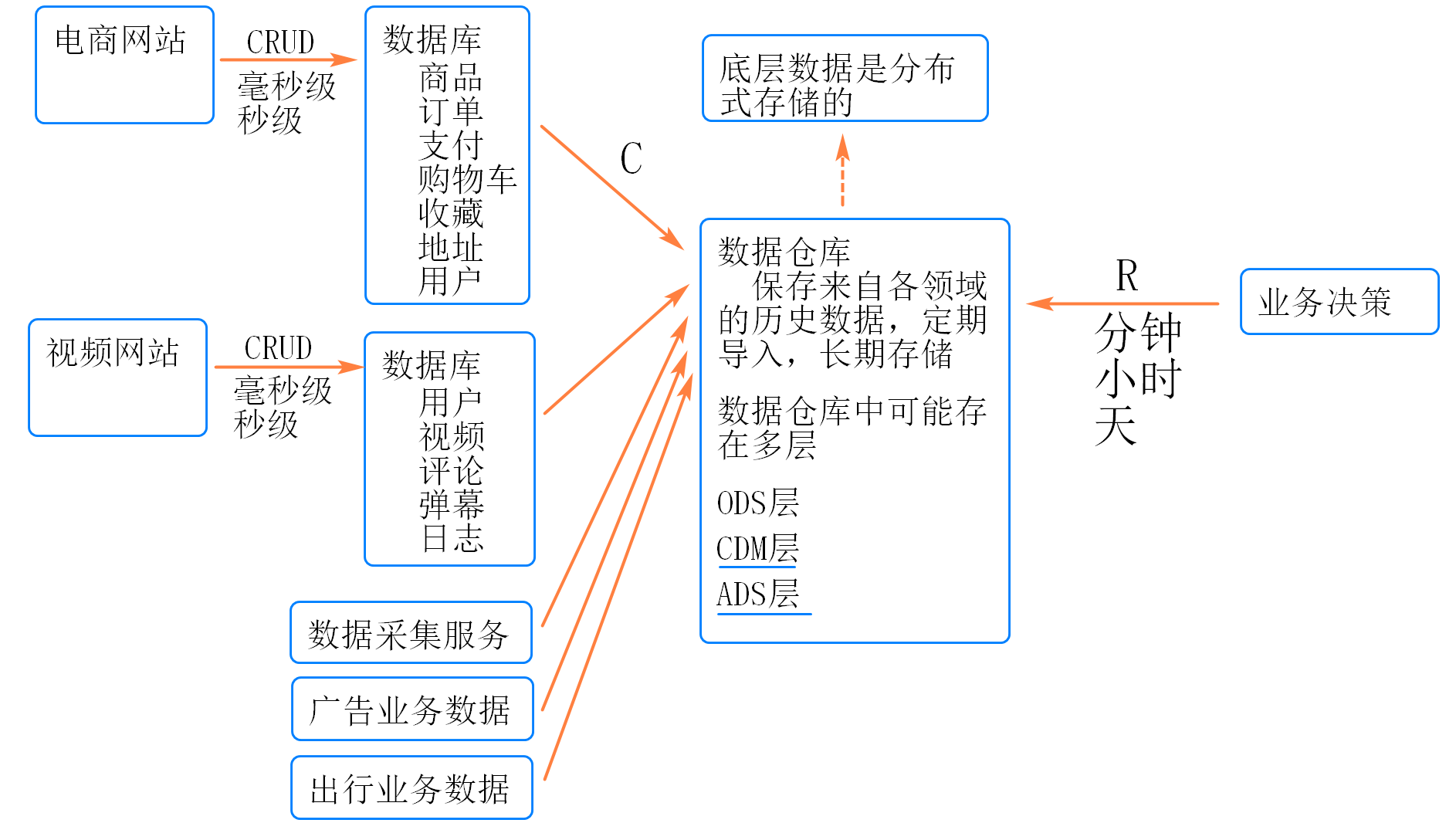
7.数仓分层
在阿里巴巴的数据体系中,我们建议将数据仓库分为三层,自下而上为:数据引入层(ODS,Operation Data Store)、数据公共层(CDM,Common Data Model)和数据应用层(ADS,Application Data Service)。
数据仓库的分层和各层级用途如下图所示。
数据引入层ODS(Operation Data Store):存放未经过处理的原始数据至数据仓库系统,结构上与源系统保持一致,是数据仓库的数据准备区。主要完成基础数据引入到MaxCompute的职责,同时记录基础数据的历史变化。
数据公共层CDM(Common Data Model,又称通用数据模型层),包括DIM维度表、DWD和DWS,由ODS层数据加工而成。主要完成数据加工与整合,建立一致性的维度,构建可复用的面向分析和统计的明细事实表,以及汇总公共粒度的指标。
公共维度层(DIM):基于维度建模理念思想,建立整个企业的一致性维度。降低数据计算口径和算法不统一风险。
公共维度层的表通常也被称为逻辑维度表,维度和维度逻辑表通常一一对应。
公共汇总粒度事实层(DWS):以分析的主题对象作为建模驱动,基于上层的应用和产品的指标需求,构建公共粒度的汇总指标事实表,以宽表化手段物理化模型。构建命名规范、口径一致的统计指标,为上层提供公共指标,建立汇总宽表、明细事实表。
公共汇总粒度事实层的表通常也被称为汇总逻辑表,用于存放派生指标数据。
明细粒度事实层(DWD):以业务过程作为建模驱动,基于每个具体的业务过程特点,构建最细粒度的明细层事实表。可以结合企业的数据使用特点,将明细事实表的某些重要维度属性字段做适当冗余,即宽表化处理。
明细粒度事实层的表通常也被称为逻辑事实表。
数据应用层ADS(Application Data Service):存放数据产品个性化的统计指标数据。根据CDM与ODS层加工生成。
该数据分类架构在ODS层分为三部分:数据准备区、离线数据和准实时数据区。整体数据分类架构如下图所示。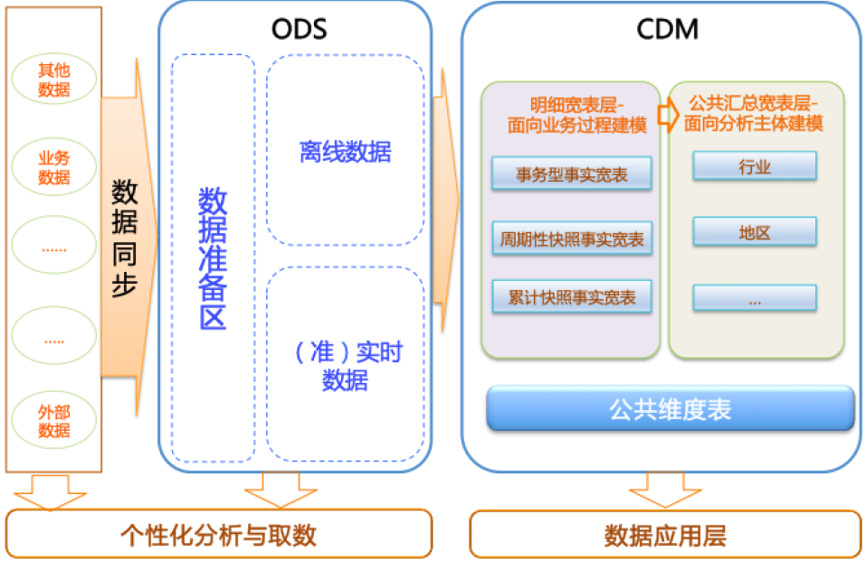 在本教程中,从交易数据系统的数据经过DataWorks数据集成,同步到数据仓库的ODS层。经过数据开发形成事实宽表后,再以商品、地域等为维度进行公共汇总。
在本教程中,从交易数据系统的数据经过DataWorks数据集成,同步到数据仓库的ODS层。经过数据开发形成事实宽表后,再以商品、地域等为维度进行公共汇总。
整体的数据流向如下图所示。其中,ODS层到DIM层的ETL(萃取(Extract)、转置(Transform)及加载(Load))处理是在MaxCompute中进行的,处理完成后会同步到所有存储系统。ODS层和DWD层会放在数据中间件中,供下游订阅使用。而DWS层和ADS层的数据通常会落地到在线存储系统中,下游通过接口调用的形式使用。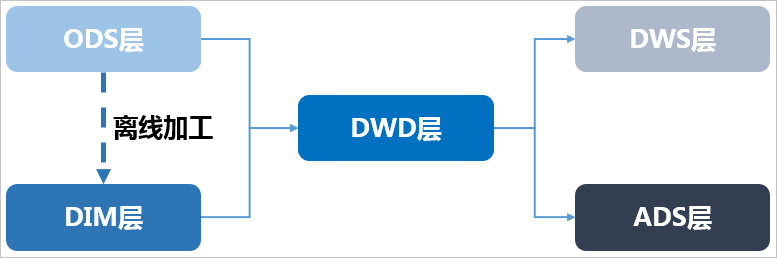
8.目标:利用大数据平台对共享单车历史数据进行预处理分析
1.上传共享单车历史数据
使用tabby的sftp工具,将案例数据.zip上传到云主机/opt/software/hadoop/data路径下

2.将数据解压缩
1.如果没有unzip命令

2.安装unzip
1 | yum install -y unzip |
3.安装完成

4.解压中文的压缩文件时乱码直接复制那个乱码的字符串然后解压
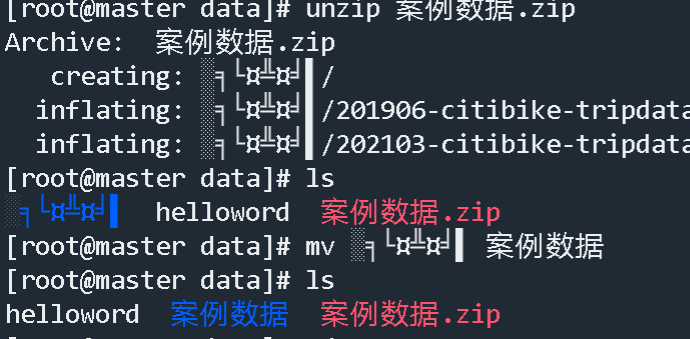
上面手欠改错了,又将案例数据改成了nybikeData
3.将数据进行预处理
要求

- 查看两条数据进入
/opt/software/hadoop/data/nybikeData
1 | #查看两条数据 |
1 | #出来的数据信息 |
1.去掉文件文件的标头行
可以通过linux的sed命令实现上述需求
1 | sed -i '1d' 201906-citibike-tripdata.csv |
处理完的数据去掉了第一行数据
2.-> 数据后续需要使用Hive去管理-> hive数据管理的数据要求去表头,去掉字段前后的双引号。
去掉文本中所有的双引号:
1 | sed -i 's/"//g' 201906-citibike-tripdata.csv |
处理完的数据
1 | 330,2019-06-01 00:00:01.5000,2019-06-01 00:05:31.7600,3602,31 Ave & 34 St,40.763154,-73.920827,3570,35 Ave & 37 St,40.7557327,-73.9236611,20348,Subscriber,1992,1 |
3.将数据上传到HDFS上
1 | hdfs dfs -put 201906-citibike-tripdata.csv /data |
查看有没有上传成功

4.需求分析:对共享单车的历史数据进行分析
对共享单车的历史数据进行分析
背景:前面的操作中实现了将纽约市2019年6月共享单车历史数据导入到HDFS上进行存储。该数据集中包含了2125371行记录,每行15个字段,接下来可以对历史数据进行分析。
需求:2019年6月每一天不同性别的用户的骑行数量
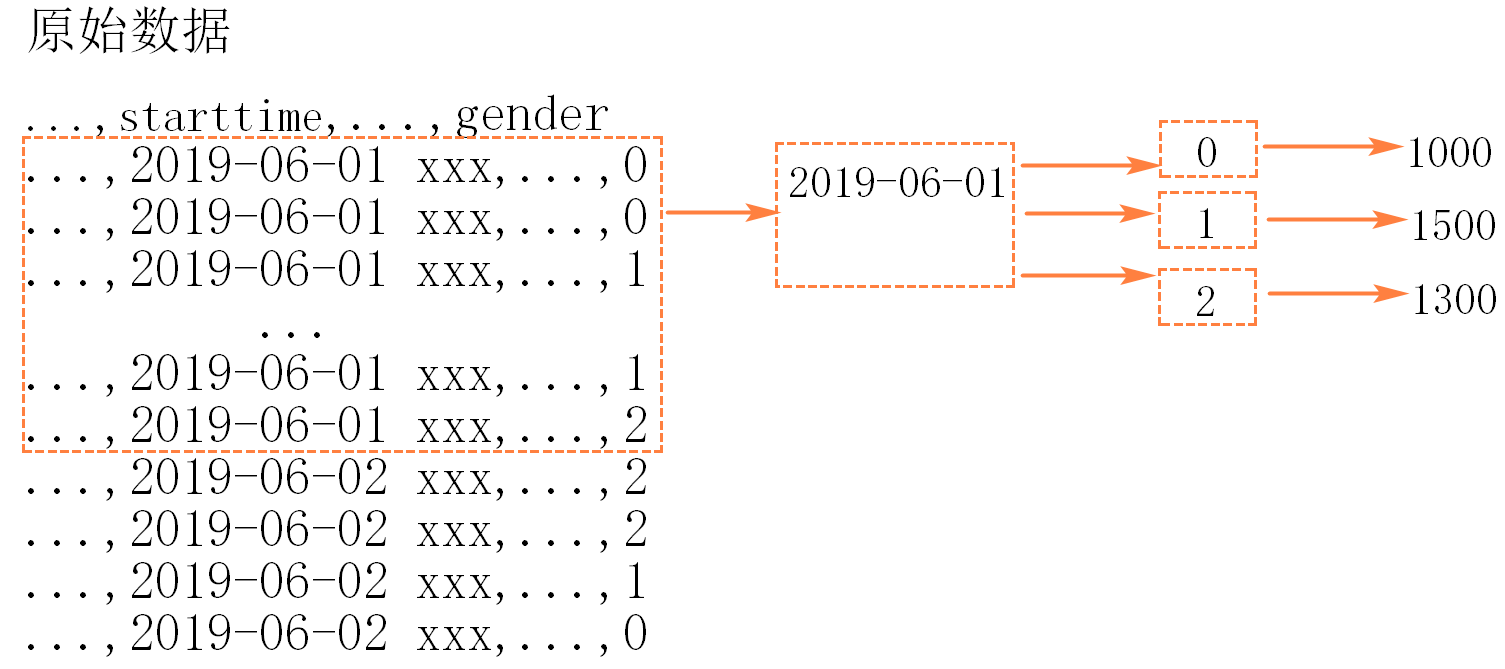
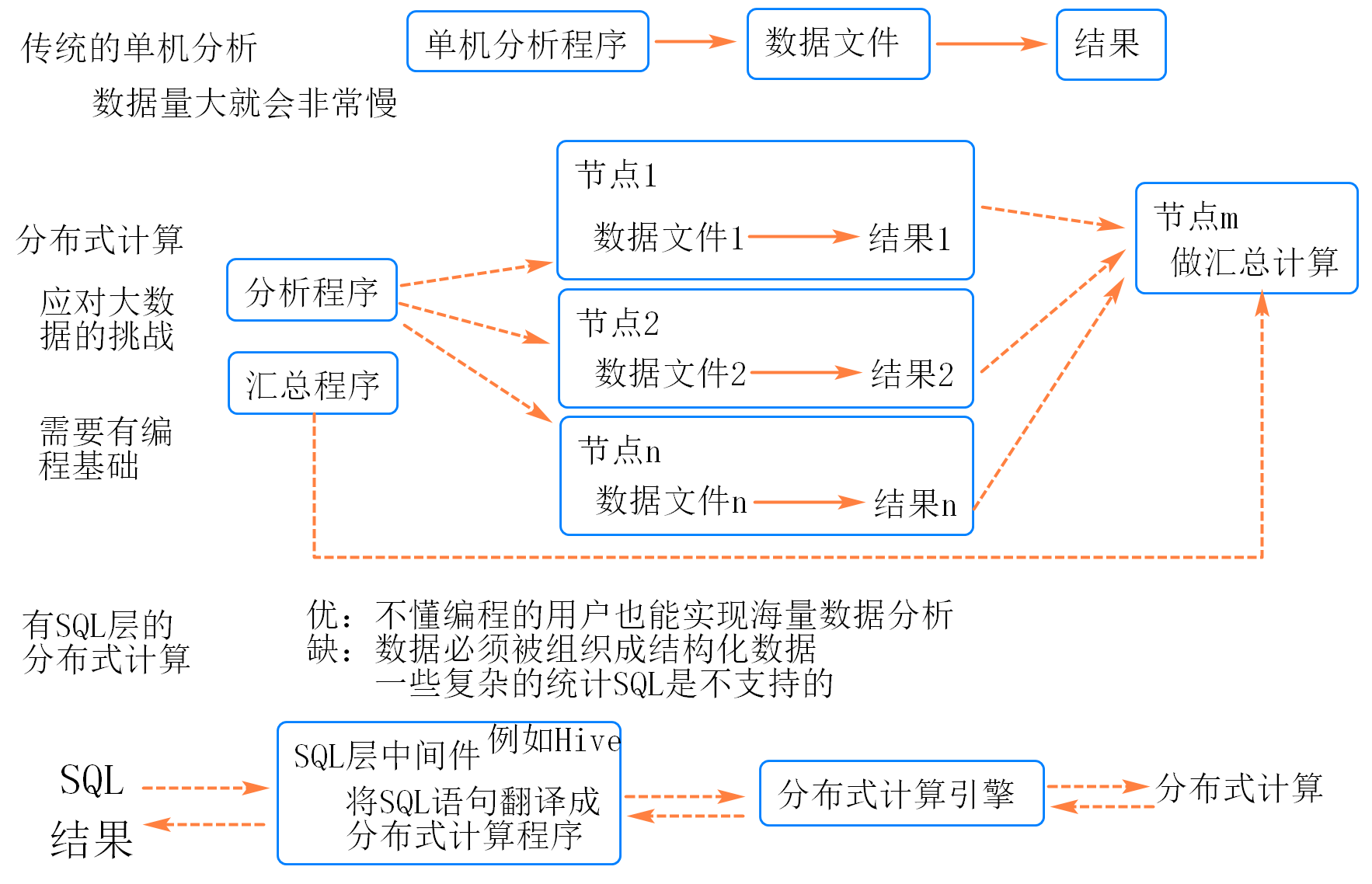
数据仓库
数据仓库,英文名称为Data Warehouse,可简写为DW或DWH。数据仓库,是为企业所有级别的决策制定过程,提供所有类型数据支持的战略集合。
在云主机上安装Hive
使用Hive管理共享单车历史数据
在Hive中建库建表,以便管理共享单车历史数据
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24-- 创建项目对应的库
create database nybikedb;
-- 使用库
use nybikedb;
-- 在库下创建表
create table trip_data_201906(
tripduration int,
starttime string,
stoptime string,
start_station_id int,
start_station_name string,
start_station_latitude double,
start_station_longitude double,
end_station_id int,
end_station_name string,
end_station_latitude double,
end_station_longitude double,
bikeid int,
usertype string,
birth_year int,
gender int
)row format delimited fields terminated by ',';将HDFS上的数据导入到Hive的表中
1
2
3
4
5
6
7
8-- 导入数据
load data inpath '/data/201906-citibike-tripdata.csv' into table nybikedb.trip_data_201906;
-- 查看表中数据行数
select count(*) from nybikedb.trip_data_201906;
-- 查看表中一行记录
select * from nybikedb.trip_data_201906 limit 1;使用HiveQL对数据进行统计分析
1
2
3
4
5-- 2019年6月每一天不同性别的用户的骑行数量
select day(starttime) as day, gender, count(*) as count
from nybikedb.trip_data_201906
group by day(starttime), gender
order by day, gender;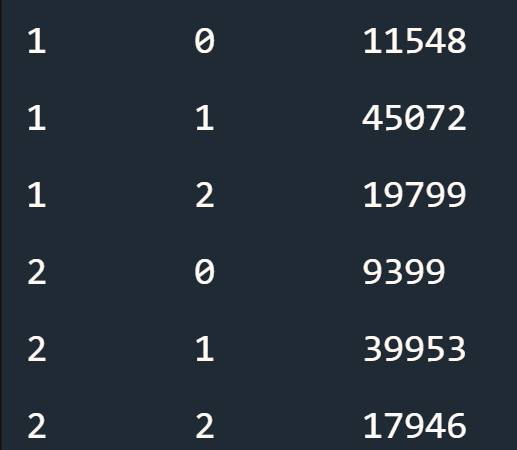
上述查询的结果只是存在在内存中,无法持久化,无法复用,如果分析的结果被复用,应该在Hive中先创建一个结果表,再使用
insert into语句搭配select语句,将统计的结果直接写入结果表具体操作
1
2
3
4
5
6
7
8
9
10
11
12
13-- 在hive中创建结果表
create table nybikedb.day_gender_count(
day int,
gender int,
count int
)row format delimited fields terminated by ',';
-- 统计数据并将结果写入结果表
insert into nybikedb.day_gender_count
select day(starttime) as day, gender, count(*) as count
from nybikedb.trip_data_201906
group by day(starttime), gender
order by day, gender;
将数据从Hive导入Mariadb
使用Sqoop完成该需求。
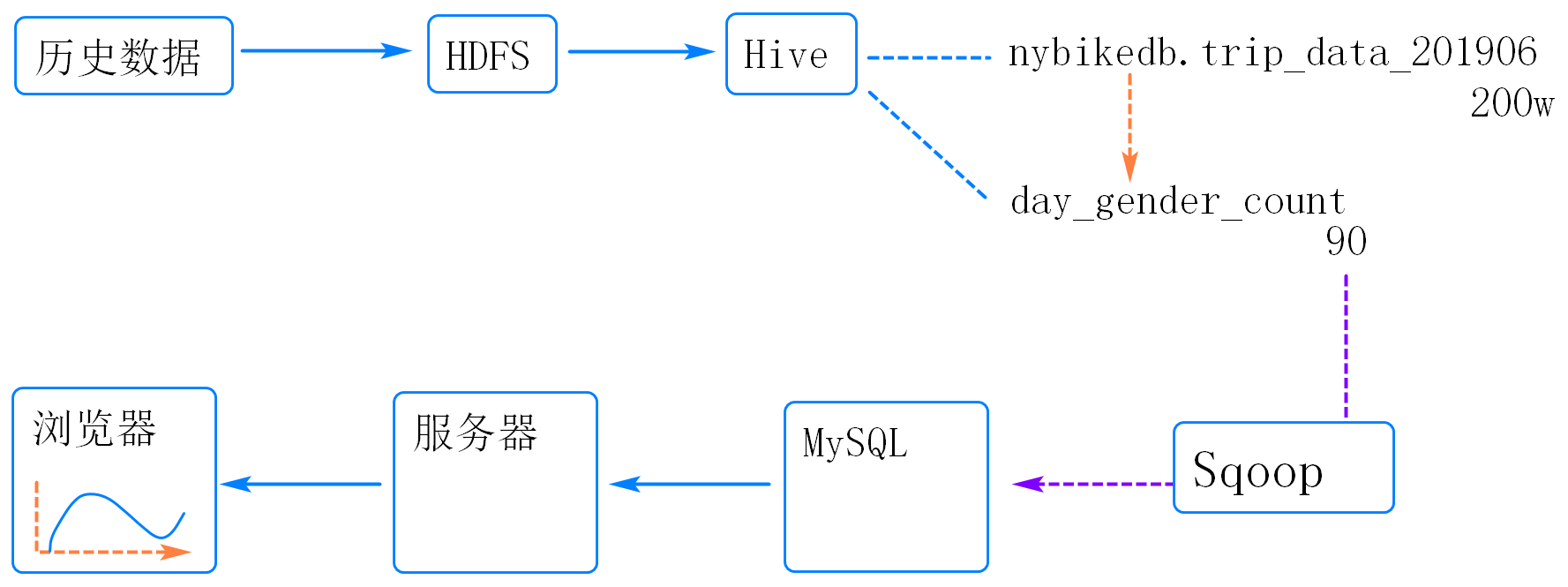
1. 在云主机的MariaDB中创建用于接收数据的表
-- 登录虚拟机的Mariadb
mysql -uroot -proot
-- 以下为mysql中的操作,建表时需要注意表中字段名称和个数需要与hive中的表一致,但是字段类型要调整为mysql的类型,主要就是讲string调整为char或者varchar
use nybikedb;
create table day_gender_count(
day int comment '数据的日期',
gender int comment '用户性别,0-未知,1-男性,2-女性',
count int comment '日骑行总数'
);
2. 使用sqoop命令将hive数据导入到MariaDB中
以下在虚拟机的终端中操作,操作前需要启动hdfs和yarn
sqoop export \
--connect jdbc:mysql://localhost:3306/nybikedb \
--username root \
--password root \
--table day_gender_count \
--fields-terminated-by ',' \
--export-dir /hive/warehouse/nybikedb.db/day_gender_count
其中:
--connect:指定连接的关系型数据库的url--username:关系型数据库的用户名--password:关系型数据库的密码--table:关系型数据库中的表名--fields-terminated-by:要导入的数据文件的分隔符,即hive中声明表时使用的字段分隔符--export-dir:hive表对应的数据在HDFS上的存储目录,目录的最后一级对应的是hive上的表名
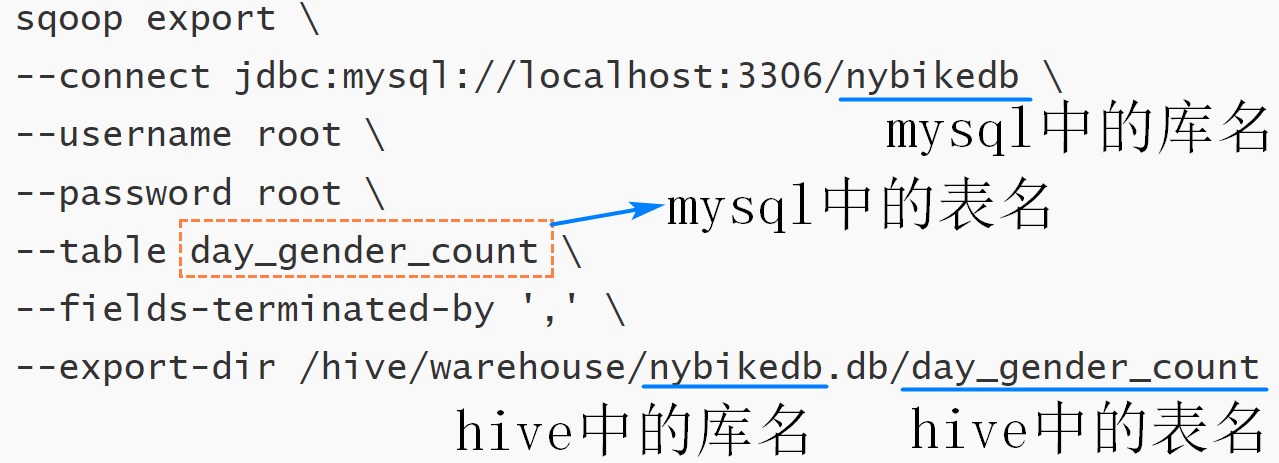
如果hive中的目标表使用了分区,那么sqoop导出数据时会抛出异常,因为目标文件夹下不是数据文件,而是分区的子文件夹。这里可以在hive上新建一张临时表,去掉分区信息,并保证数据的顺序,再使用sqoop导出该表的数据到MariaDB中。
在本地IDEA的项目中访问云主机数据库
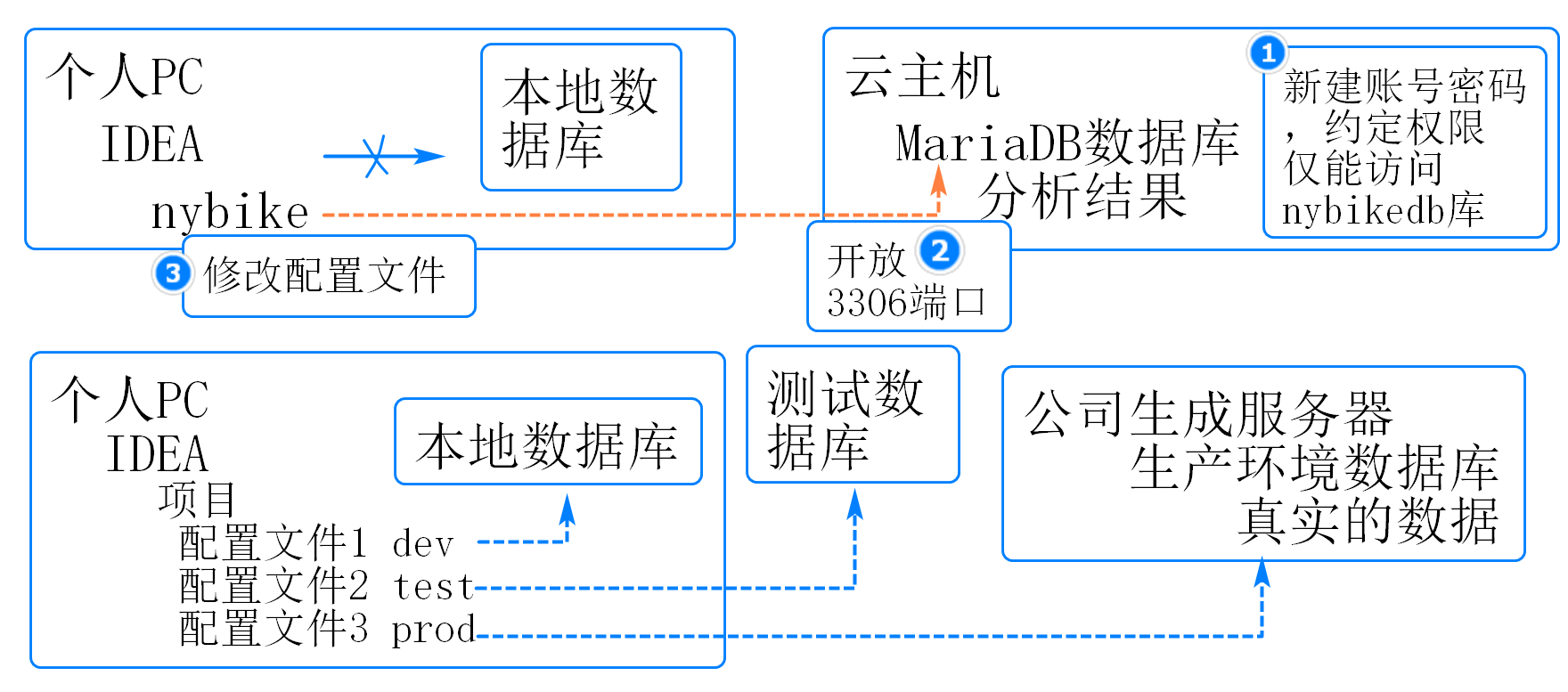
在云主机的数据库中新建账号,限定权限
1
2
3
4
5
6
7mysql -uroot -proot
grant all on nybikedb.* to user@'%' identified by 'mysqlDWP135@';
flush privileges;
exit;开放云主机的3306端口
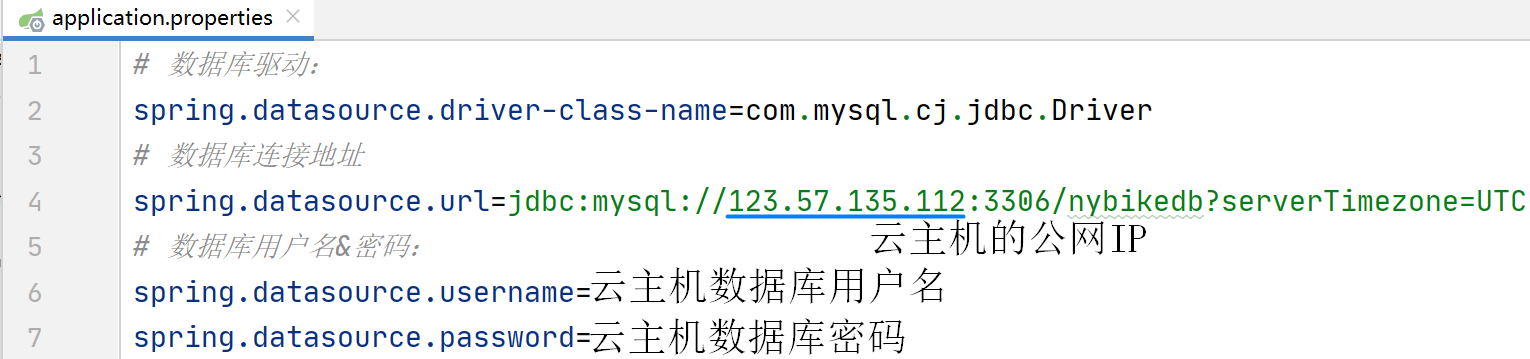
修改本地IDEA中nybike项目的配置文件
修改src/main/resources/application.properties中的配置
DBeaver连接Hive问题
修改hadoop的配置文件
修改 core-site.xml文件
vim /usr/local/hadoop/etc/hadoop/core-site.xml
1 | <property> |
关闭文件权限检查:
hdfs-site.xml
1 | <property> |
通过以下命令启动远程服务:
1 | nohup hive --service metastore & |
远程服务对外的端口是10000,启动成功后,使用netstat命令验证:
1 | netstat -antpl|grep 10000 |
下载cloudera版本的JDBC驱动
下载地址:https://www.cloudera.com/downloads.html
1.第一步
2.第二步
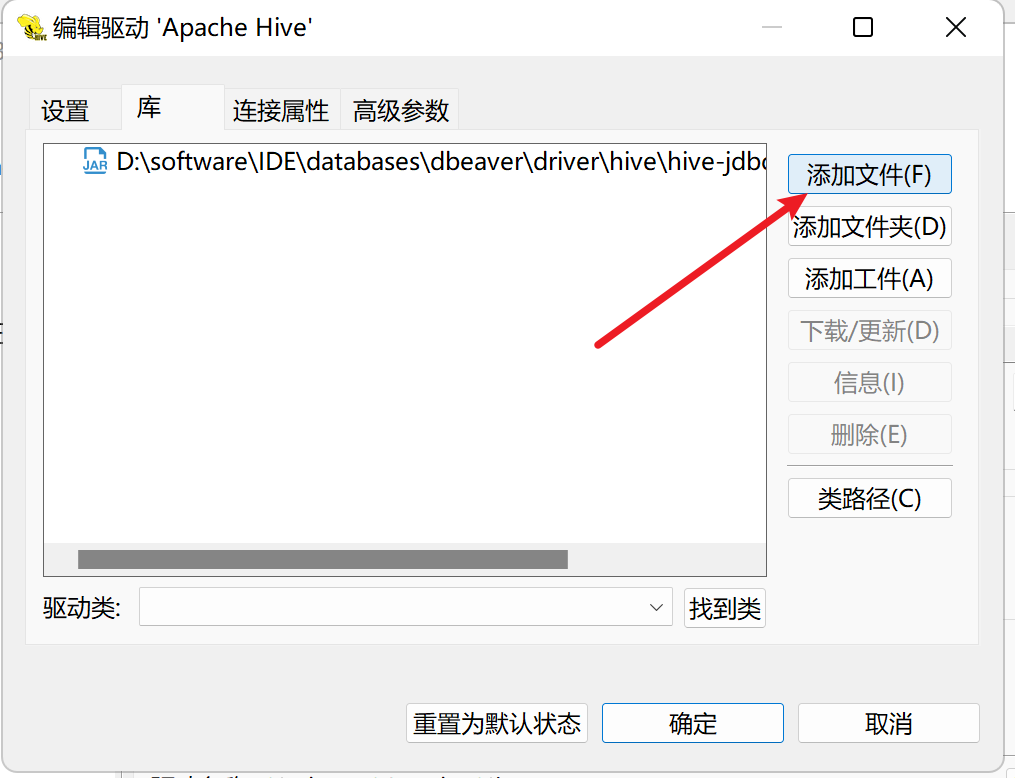
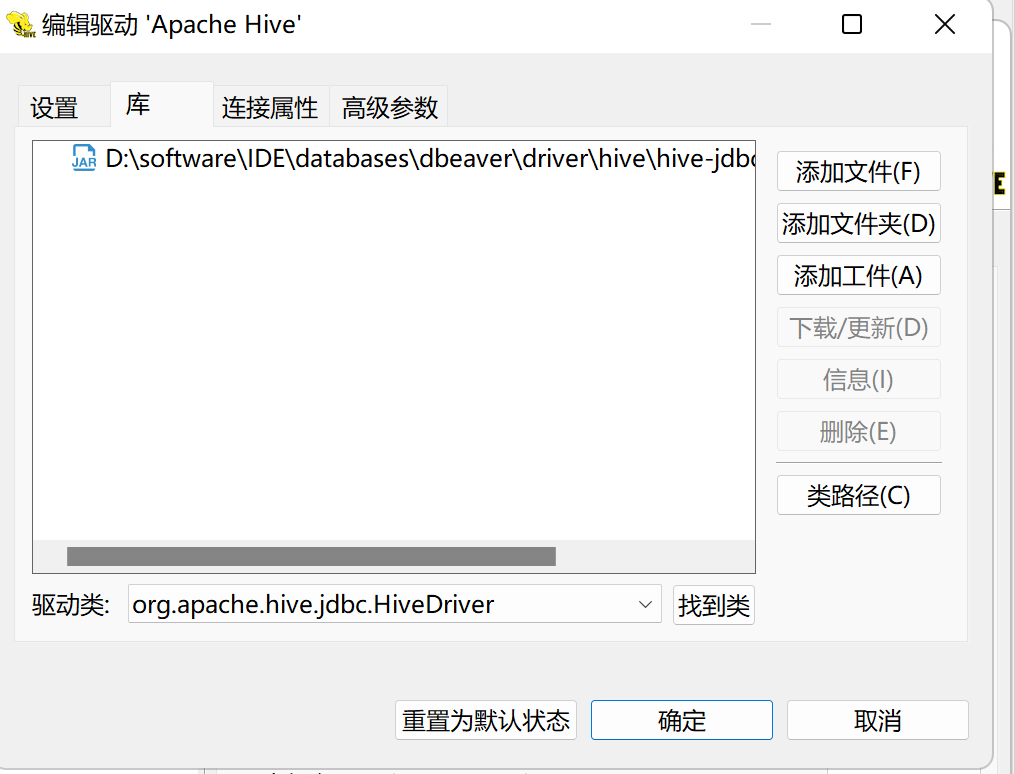
3.第三步打开添加,找到驱动类
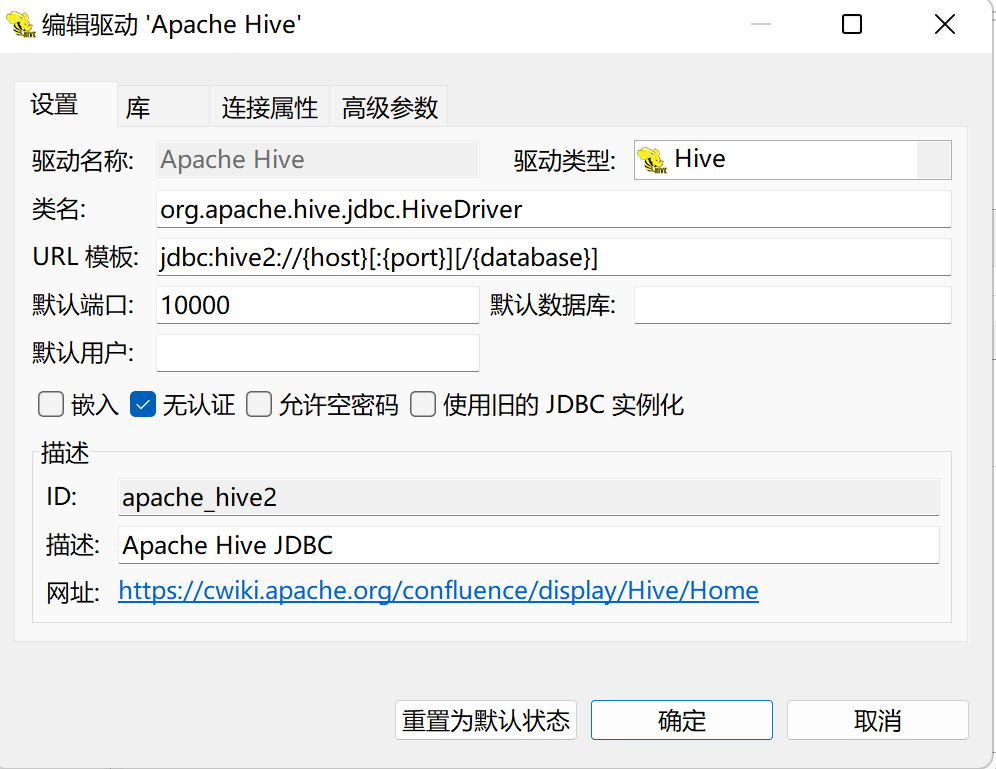
4.第四步选择无认证
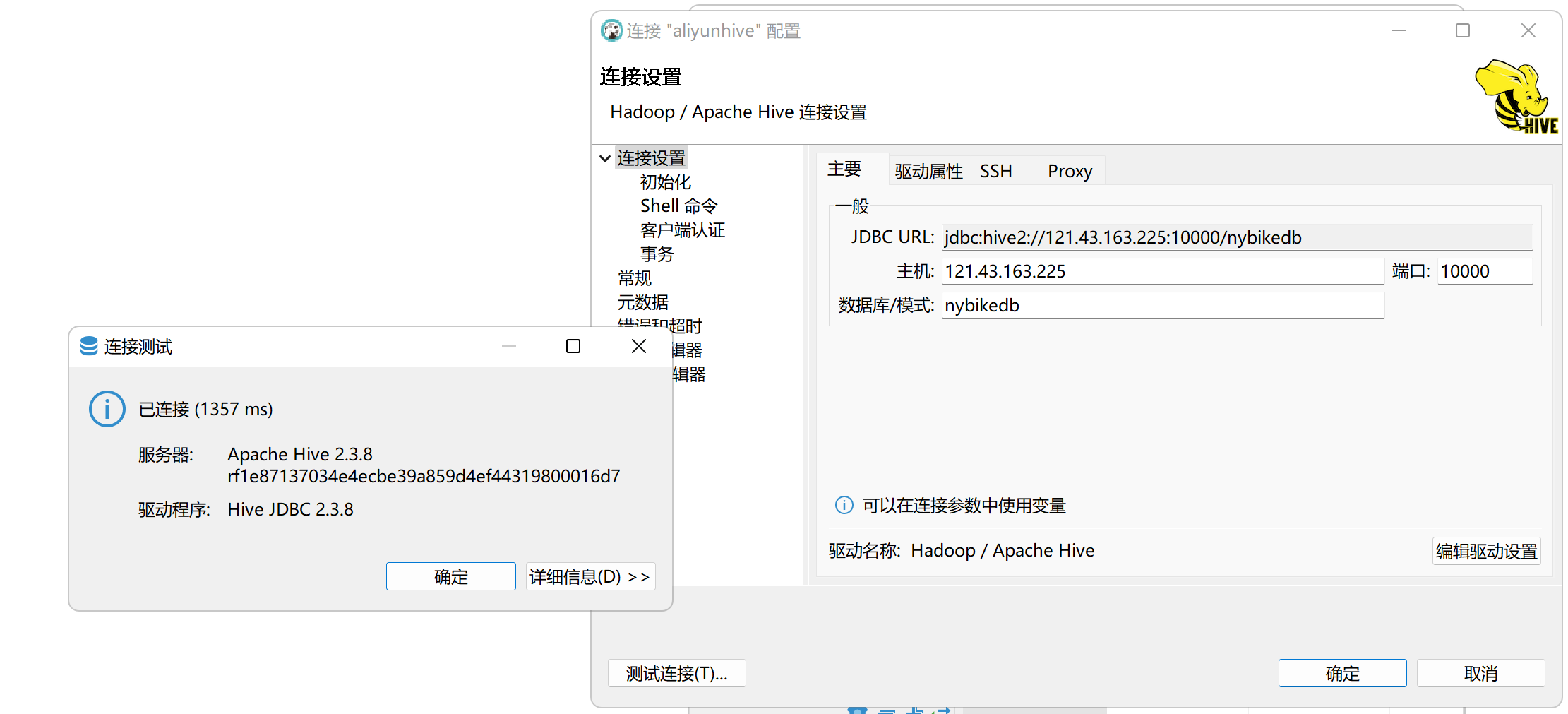
第五步连接成功
Hive远程访问操作
https://blog.51cto.com/candon123/2048202