[TOC]
Hadoop HA 高可用
6.1 HA 概述
(1) 所谓 HA(High Availablity),即高可用(7*24 小时不中断服务)。
(2) 实现高可用最关键的策略是消除单点故障。HA 严格来说应该分成各个组件的 HA 机制:HDFS 的 HA 和 YARN 的 HA。
(3) NameNode 主要在以下两个方面影响 HDFS 集群
- ➢ NameNode 机器发生意外,如宕机,集群将无法使用,直到管理员重启
- ➢ NameNode 机器需要升级,包括软件、硬件升级,此时集群也将无法使用
HDFS HA 功能通过配置多个 NameNodes(Active/Standby)实现在集群中对 NameNode 的热备来解决上述问题。如果出现故障,如机器崩溃或机器需要升级维护,这时可通过此种方式将 NameNode 很快的切换到另外一台机器。
6.2 HDFS-HA 集群搭建
当前 HDFS 集群的规划
| hadoop102 | hadoop103 | hadoop104 |
|---|---|---|
| NameNode | Secondarynamenode | |
| DataNode | DataNode | DataNode |
HA 的主要目的是消除 namenode 的单点故障,需要将 hdfs 集群规划成以下模样
| hadoop102 | hadoop103 | hadoop104 |
|---|---|---|
| NameNode | NameNode | NameNode |
| DataNode | DataNode | DataNode |
6.2.1 HDFS-HA 核心问题
1)怎么保证三台 namenode 的数据一致
a.Fsimage:让一台 nn 生成数据,让其他机器 nn 同步
b.Edits:需要引进新的模块 JournalNode 来保证 edtis 的文件的数据一致性
2)怎么让同时只有一台 nn 是 active,其他所有是 standby 的
a.手动分配
b.自动分配
3)****2nn 在 ha 架构中并不存在,定期合并 fsimage 和 edtis 的活谁来干
由 standby 的 nn 来干
4)如果 nn 真的发生了问题,怎么让其他的 nn 上位干活
a.手动故障转移
b.自动故障转移
6.3 HDFS-HA 手动模式
6.3.1 环境准备
(1)修改 IP
(2)修改主机名及主机名和 IP 地址的映射
(3)关闭防火墙
(4)ssh 免密登录
(5)安装 JDK,配置环境变量等
6.3.2 规划集群
| hadoop102 | hadoop103 | hadoop104 |
|---|---|---|
| NameNode | NameNode | NameNode |
| JournalNode | JournalNode | JournalNode |
| DataNode | DataNode | DataNode |
6.3.3 配置 HDFS-HA 集群
1)官方地址:http://hadoop.apache.org/
2)在 opt 目录下创建一个 ha 文件夹
1 | [atguigu@hadoop102 ~]$ cd /opt |
3)将**/opt/module/下的 hadoop-3.1.3 拷贝到/opt/ha** 目录下(记得删除 data 和 log 目录)
1 | [atguigu@hadoop102 opt]$ cp -r /opt/module/hadoop-3.1.3 /opt/module/ha |
4)配置 core-site.xml
1 | <configuration> |
5)配置 hdfs-site.xml
1 | <configuration> |
6)分发配置好的 hadoop 环境到其他节点
6.3.4 启动 HDFS-HA 集群
1)将 HADOOP_HOME 环境变量更改到 HA 目录**(三台机器)**
1 | [atguigu@hadoop102 ~]$ sudo vim /etc/profile.d/my_env.sh |
将 HADOOP_HOME 部分改为如下
1 | #HADOOP_HOME |
去三台机器上 source 环境变量
1 | [atguigu@hadoop102 ~]$source /etc/profile |
2)在各个 JournalNode 节点上,输入以下命令启动 journalnode 服务
1 | [atguigu@hadoop102 ~]$ hdfs --daemon start journalnode |
3)在**[nn1]**上,对其进行格式化,并启动
1 | [atguigu@hadoop102 ~]$ hdfs namenode -format |
4)在[nn2]和[nn3]上,同步 nn1 的元数据信息
1 | [atguigu@hadoop103 ~]$ hdfs namenode -bootstrapStandby |
5)启动[nn2]和[nn3]
1 | [atguigu@hadoop103 ~]$ hdfs --daemon start namenode |

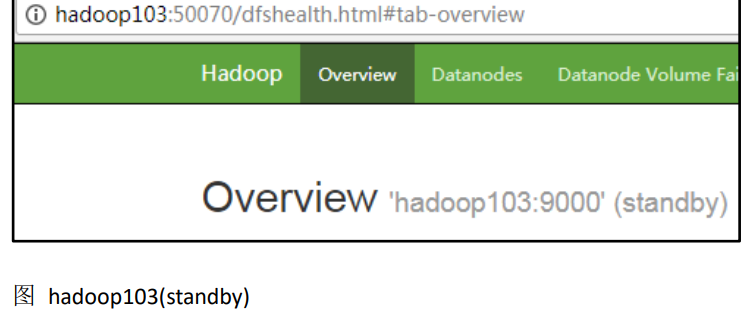
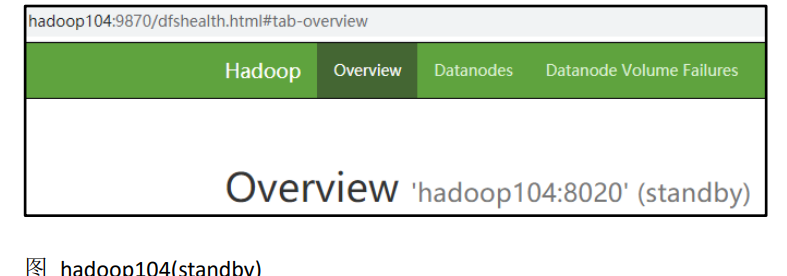
7)在所有节点上,启动 datanode
1 | [atguigu@hadoop102 ~]$ hdfs --daemon start datanode |
8)将**[nn1]**切换为 Active
1 | [atguigu@hadoop102 ~]$ hdfs haadmin -transitionToActive nn1 |
9)查看是否 Active
1 | [atguigu@hadoop102 ~]$ hdfs haadmin -getServiceState nn1 |
6.4 HDFS-HA 自动模式
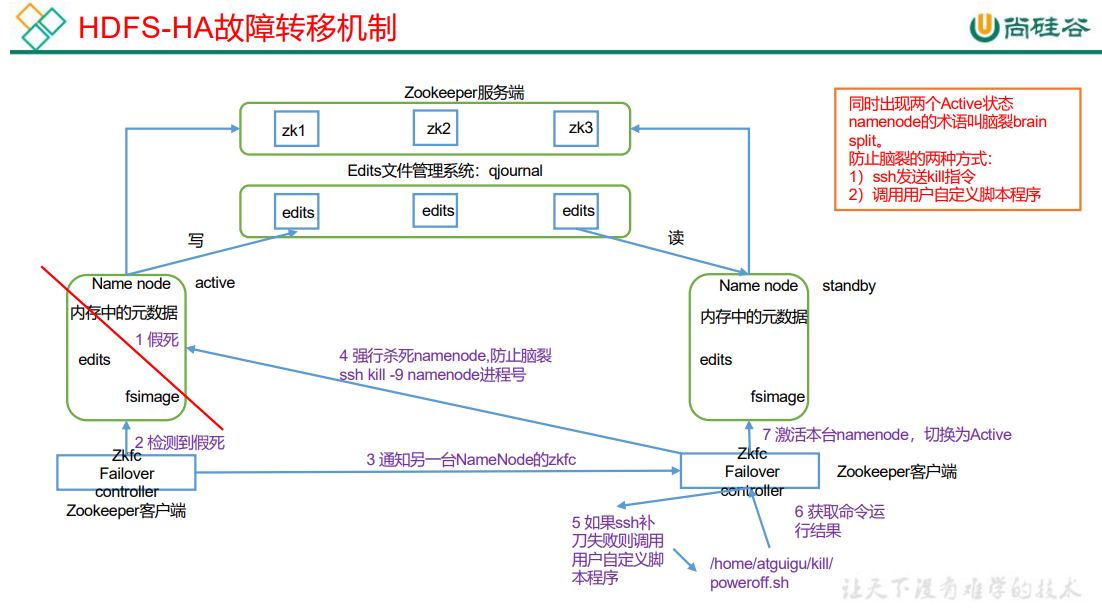
6.4.1 HDFS-HA 自动故障转移工作机制
自动故障转移为 HDFS 部署增加了两个新组件:ZooKeeper 和 ZKFailoverController (ZKFC)进程,如图所示。ZooKeeper 是维护少量协调数据,通知客户端这些数据的改变和监视客户端故障的高可用服务。
6.4.2 HDFS-HA 自动故障转移的集群规划
| hadoop102 | hadoop103 | hadoop104 |
|---|---|---|
| NameNode | NameNode | NameNode |
| JournalNode | JournalNode | JournalNode |
| DataNode | DataNode | DataNode |
| Zookeeper | Zookeeper | Zookeeper |
| ZKFC | ZKFC | ZKFC |
6.4.3 配置 HDFS-HA 自动故障转移
1)具体配置
(1)在 hdfs-site.xml 中增加
1 | <!-- 启用nn故障自动转移 --> |
(2)在 core-site.xml 文件中增加
1 | <!-- 指定 zkfc 要连接的 zkServer 地址 --> |
(3)修改后分发配置文件
1 | [atguigu@hadoop102 etc]$ pwd |
2)启动
(1)关闭所有 HDFS 服务:
1 | [atguigu@hadoop102 ~]$ stop-dfs.sh |
(2)启动 Zookeeper 集群:
1 | [atguigu@hadoop102 ~]$ zkServer.sh start |
(3)启动 Zookeeper 以后,然后再初始化 HA 在 Zookeeper 中状态:
1 | [atguigu@hadoop102 ~]$ hdfs zkfc -formatZK |
(4)启动 HDFS 服务:
1 | [atguigu@hadoop102 ~]$ start-dfs.sh |
(5)可以去 zkCli.sh 客户端查看 Namenode 选举锁节点内容:
1 | [zk: localhost:2181(CONNECTED) 7] get -s /hadoop-ha/mycluster/ActiveStandbyElectorLock |
3)验证
(1)将 Active NameNode 进程 kill,查看网页端三台 Namenode 的状态变化
1 | [atguigu@hadoop102 ~]$ kill -9 namenode的进程id |
6.4.3 解决 NN 连接不上 JN 的问题
自动故障转移配置好以后,然后使用 start-dfs.sh 群起脚本启动 hdfs 集群,有可能会遇到 NameNode 起来一会后,进程自动关闭的问题。查看 NameNode 日志,报错信息如下:
1 | 2020-08-17 10:11:40,658 INFO org.apache.hadoop.ipc.Client: Retrying connect |
查看报错日志,可分析出报错原因是因为 NameNode 连接不上 JournalNode,而利用 jps 命令查看到三台 JN 都已经正常启动,为什么 NN 还是无法正常连接到 JN 呢?这是因为 start-dfs.sh 群起脚本默认的启动顺序是先启动 NN,再启动 DN,然后再启动 JN,并且默认的 rpc 连接参数是重试次数为 10,每次重试的间隔是 1s,也就是说启动完 NN 以后的 10s 中内,JN 还启动不起来,NN 就会报错了。
core-default.xml 里面有两个参数如下:
1 | <!-- NN 连接 JN 重试次数,默认是 10 次 --> |
解决方案:遇到上述问题后,可以稍等片刻,等 JN 成功启动后,手动启动下三台
NN:
1 | [atguigu@hadoop102 ~]$ hdfs --daemon start namenode |
也可以在 core-site.xml 里面适当调大上面的两个参数:
1 | <!-- NN 连接 JN 重试次数,默认是 10 次 --> |
6.5 YARN-HA 配置
6.5.1 YARN-HA 工作机制
1)官方文档:
http://hadoop.apache.org/docs/r3.1.3/hadoop-yarn/hadoop-yarn-site/ResourceManagerHA.html
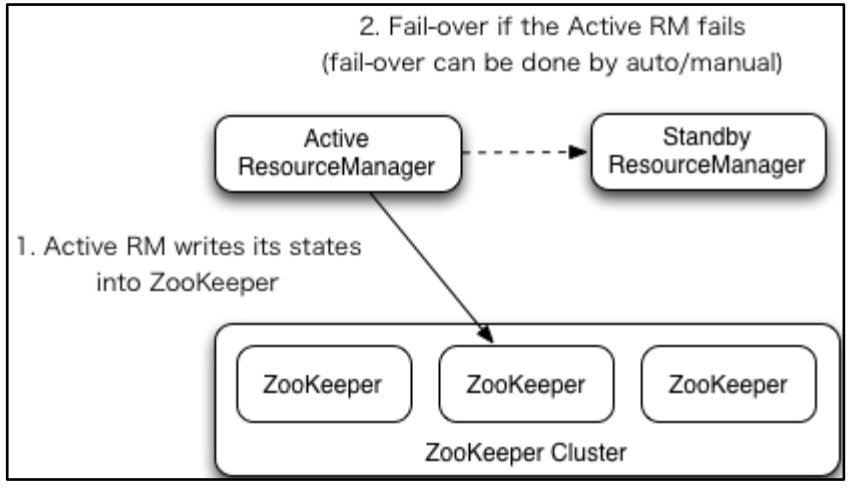
2)YARN-HA 工作机制
1)环境准备
(1)修改 IP
(2)修改主机名及主机名和 IP 地址的映射
(3)关闭防火墙
(4)ssh 免密登录
(5)安装 JDK,配置环境变量等
(6)配置 Zookeeper 集群
2)规划集群
| hadoop102 | hadoop103 | hadoop104 |
|---|---|---|
| ResourceManager | ResourceManager | ResourceManager |
| NodeManager | NodeManager | NodeManager |
| Zookeeper | Zookeeper | Zookeeper |
3)核心问题
**a .**如果当前 active rm 挂了,其他 rm 怎么将其他 standby rm 上位
核心原理跟 hdfs 一样,利用了 zk 的临时节点
b. 当前 rm 上有很多的计算程序在等待运行**,**其他的 rm 怎么将这些程序接手过来接着跑
rm 会将当前的所有计算程序的状态存储在 zk 中,其他 rm 上位后会去读取,然后接着跑
4)具体配置
(1)yarn-site.xml
1 | <configuration> |
(2)同步更新其他节点的配置信息,分发配置文件
1 | [atguigu@hadoop102 etc]$ xsync hadoop/ |
4)启动 YARN
(1)在 hadoop102 或者 hadoop103 中执行:
1 | [atguigu@hadoop102 ~]$ start-yarn.sh |
(2)查看服务状态
1 | [atguigu@hadoop102 ~]$ yarn rmadmin -getServiceState rm1 |
(3)可以去 zkCli.sh 客户端查看 ResourceManager 选举锁节点内容:
1 | [atguigu@hadoop102 ~]$ zkCli.sh |
(4)web 端查看 hadoop102:8088 和 hadoop103:8088 的 YARN 的状态
将整个 ha 搭建完成后,集群将形成以下模样
| hadoop102 | hadoop103 | hadoop104 |
|---|---|---|
| NameNode | NameNode | NameNode |
| JournalNode | JournalNode | JournalNode |
| DataNode | DataNode | DataNode |
| Zookeeper | Zookeeper | Zookeeper |
| ZKFC | ZKFC | ZKFC |
| ResourceManager | ResourceManager | ResourceManager |
| NodeManager | NodeManager | NodeManager |