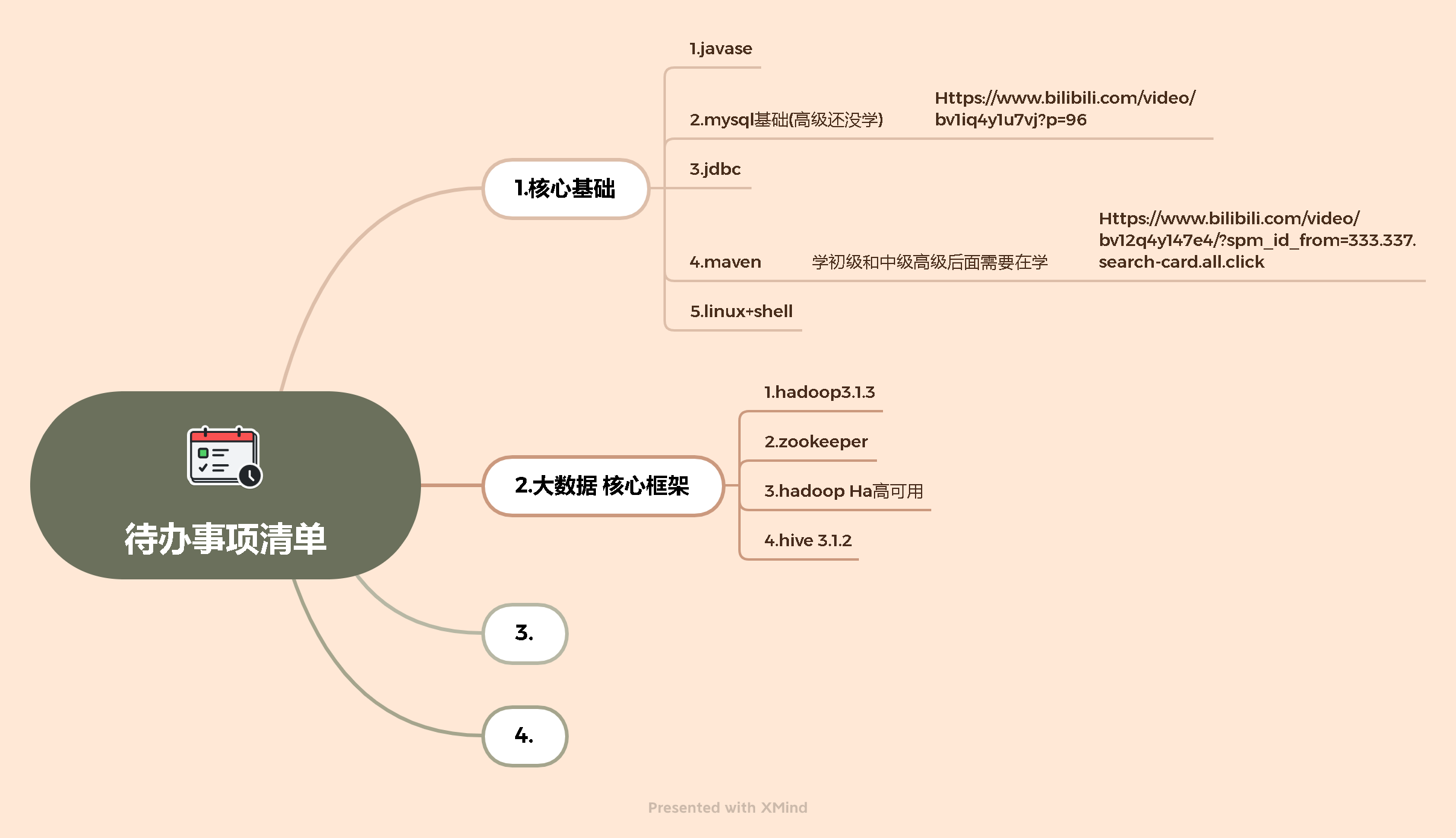
[TOC]
IntelliJ IDEA 常用快捷键一览表


第1组:通用型
| 说明 | 快捷键 |
|---|---|
| 复制代码-copy | ctrl + c |
| 粘贴-paste | ctrl + v |
| 剪切-cut | ctrl + x |
| 撤销-undo | ctrl + z |
| 反撤销-redo | ctrl + shift + z |
| 保存-save all | ctrl + s |
| 全选-select all | ctrl + a |
[TOC]
(1) 所谓 HA(High Availablity),即高可用(7*24 小时不中断服务)。
(2) 实现高可用最关键的策略是消除单点故障。HA 严格来说应该分成各个组件的 HA 机制:HDFS 的 HA 和 YARN 的 HA。
(3) NameNode 主要在以下两个方面影响 HDFS 集群
HDFS HA 功能通过配置多个 NameNodes(Active/Standby)实现在集群中对 NameNode 的热备来解决上述问题。如果出现故障,如机器崩溃或机器需要升级维护,这时可通过此种方式将 NameNode 很快的切换到另外一台机器。
[TOC]
尚硅谷大数据技术之Hadoop(HDFS)
(作者:尚硅谷大数据研发部)
版本:V3.3
1)HDFS产生背景
随着数据量越来越大,在一个操作系统存不下所有的数据,那么就分配到更多的操作系统管理的磁盘中,但是不方便管理和维护,迫切需要一种系统来管理多台机器上的文件,这就是分布式文件管理系统。HDFS只是分布式文件管理系统中的一种。
2)HDFS定义
HDFS(Hadoop Distributed File System),它是一个文件系统,用于存储文件,通过目录树来定位文件;其次,它是分布式的,由很多服务器联合起来实现其功能,集群中的服务器有各自的角色。
HDFS的使用场景:适合一次写入,多次读出的场景。一个文件经过创建、写入和关闭之后就不需要改变。